AWS Feed
Understanding the key capabilities of Amazon SageMaker Feature Store

One of the challenging parts of machine learning (ML) is feature engineering, the process of transforming data to create features for ML. Features are processed data signals used for training ML models and for deployed models to make accurate predictions. Data scientists and ML engineers can spend up to 60-70% of their time on feature engineering. It’s also typical to have this work repeated by different teams within an organization who use the same data to build ML models for different solutions, further increasing effort levels for feature engineering. Moreover, it’s important that the generated features should be available for both training and real-time inference use cases, to ensure consistency between model training and inference serving.
A purpose-built feature store for ML is needed to ensure both high-quality ML predictions with a consistent set of features, and cost reduction by eliminating duplicate feature engineering effort and storage overhead. Consistent features are needed between different parts of an organization, and between training and inference for any given ML model. There is also a need for feature stores to meet the high performance, scale, and availability requirements to serve features in near-real time for inferences. Because of this, organizations are often forced to do the heavy lifting of building and maintaining feature store systems, which can become expensive and difficult to maintain.
At AWS we are constantly listening to our customers and building solutions and services that delight them. We heard from many customers about the pain their data science and data engineering teams face when managing features, and used those inputs to build the Amazon SageMaker Feature Store, which was launched at re:Invent on December 1, 2020. Amazon SageMaker Feature Store is a fully managed, purpose-built repository to securely store, update, retrieve, and share ML features.
Although there is a lot to unpack in terms of the capabilities that SageMaker Feature Store brings to the table, in this post, we focus on key capabilities for data ingestion, data access, and security and access control.
Overview of SageMaker Feature Store
As a purpose-built feature store for ML, SageMaker Feature Store is designed to enable you to do the following:
- Securely store and serve features for real-time and batch applications – SageMaker Feature Store serves features at a very low latency for real-time use-cases. It enables you to use ML to make near-real time decisions by enabling feature vector retrievals with low millisecond latencies (p95 latency lower than 10 milliseconds for a 15-kilobyte payload).
- Accelerate model development by sharing and reusing features – Feature engineering is a long and tedious process that often gets repeated by multiple teams within an organization working on the same data. SageMaker Feature Store enables data scientists to spend less time on data preparation and feature computation, and more time on ML innovation, by letting them discover and reuse existing engineered features across the organization.
- Provide historical data access – Features are used for training purposes, and a good feature store should provide easy and quick access to historical feature values to recreate training datasets at a given point in time in the past. Amazon SageMaker Feature Store enables this with support for time-travel queries—querying data at a point in time—which enables you to re-create features at specific points of time in the past.
- Reduce training-serving skew – Data science teams often struggle with training-serving skew caused by data discrepancy between model training and inference serving, which can cause models to perform worse than expected in production. SageMaker Feature Store reduces training-serving skew by keeping feature consistency between training and inference.
- Enable data encryption and access control – As with other data assets, ML feature data security is paramount in all organizations. At AWS, security and operational performance are our top priorities, and SageMaker Feature Store provides a suite of capabilities for enterprise-grade data security and access control, including encryption at rest and in transit, and role-based access control using AWS Identity and Access Management (IAM).
- Guarantee a robust service level – Managed feature store production use cases need service-level guarantees, ensuring that you get the desired performance and availability, and you can rely on expert help should something go wrong. SageMaker Feature Store is backed by AWS’s unmatched reliability, scale and operational efficiency.
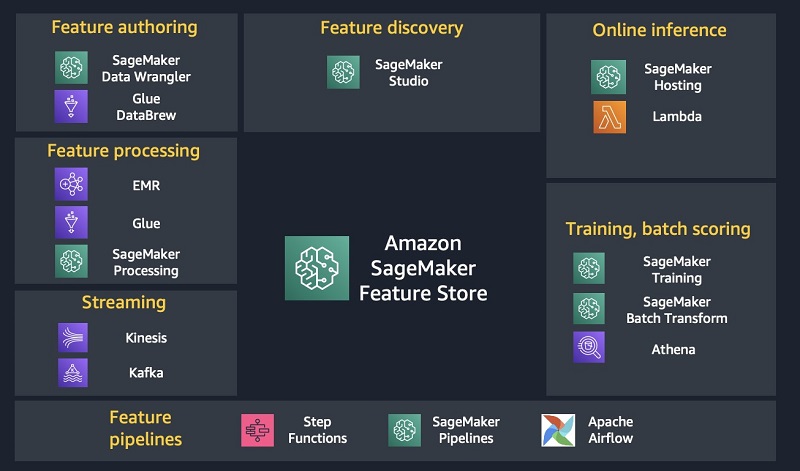
SageMaker Feature Store is designed to play a central role in ML architectures, helping you streamline the ML lifecycle, and integrating seamlessly with many other services. For example, you can use tools like AWS Glue DataBrew and SageMaker Data Wrangler for feature authoring. You can use Amazon EMR, AWS Glue, and SageMaker Processing in conjunction with SageMaker Feature Store for performing feature transformation tasks. You can use a suite of tools, including SageMaker Pipelines, AWS Step Functions, or Apache AirFlow for scheduling and orchestrating feature pipelines to automate feature engineering process flow. When you have features in the feature store, you can pull them with low latency from the online store to feed models hosted with services like SageMaker Hosting. You can use existing tools like Amazon Athena, Presto, Spark, and EMR to extract datasets from the offline store for use with SageMaker Training and batch transforms. Lastly, you can use Amazon Kinesis, Apache Kafka, and AWS Lambda for streaming feature engineering and ingestion. The following diagram illustrates some of the services that can be integrated with SageMaker Feature Store.
Before we go into more detail, we briefly introduce some SageMaker Feature Store concepts:
- Feature group – a logical grouping of ML features
- Record – a set of values for features in a feature group
- Online store – the low latency, high availability store that enables real-time lookup of records
- Offline store – the store that manages historical data in your Amazon Simple Storage Service (Amazon S3) bucket, and is used for exploration and model training use cases
For more information, see Get started with Amazon SageMaker Feature Store.
Data ingestion
SageMaker Feature Store provides multiple ways to ingest data, including batch ingestion, ingestion from streaming data sources and a combination of both. SageMaker Feature Store is built in a modular fashion and is designed to ingest data from a variety of sources, including directly from SageMaker Data Wrangler, or sources like Kinesis or Apache Kafka. The following diagram shows the various data ingestion and mechanisms supported by SageMaker Feature Store.
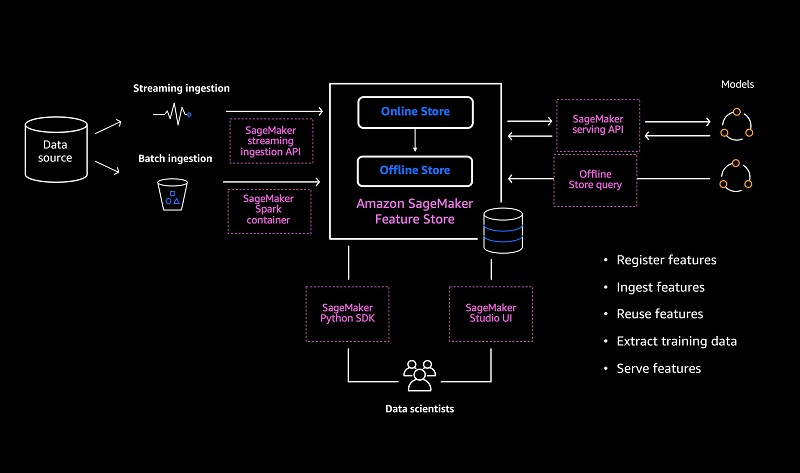
Streaming ingestion
SageMaker Feature Store provides the low latency PutRecord API, which is designed to give you millisecond-level latency and high throughput cost-optimized data ingestion. The API is designed to be called by different streams, and you can use streaming sources such as Apache Kafka, Kinesis, Spark Streaming, or another source to extract features in real-time and feed them directly into the online store, or both the online and offline store.
For even faster ingestion, the PutRecord API can be parallelized to support higher throughput writes. The data from all these PUT requests is synchronously written to the online store, and buffered and written to an offline store (Amazon S3) if that option is selected. The data is written to the offline store within a few minutes of ingestion. SageMaker Feature Store provides data and schema validations at ingestion time to ensure data quality is maintained. Validations are done to make sure that input data conforms to the defined data types and that the input record contains all features. If you have configured an offline store, SageMaker Feature Store provides automatic replication of the ingested data into the offline store for future training and historical record access use cases.
Batch ingestion
You can perform batch ingestion to SageMaker Feature Store by integrating it with your feature generation and processing pipelines. You have the flexibility to build feature pipelines with your choice of technology. After performing any data transformations and batch aggregations, the processing pipelines can ingest feature data into the SageMaker Feature Store via batch ingestion.
You can perform batch ingestion in the following 3 modes:
- Batch ingest into the online store – This can be done by calling the synchronous PutRecord API. SageMaker Feature Store gives you the flexibility to set up an online-only feature store for use cases that don’t require offline feature access, keeping your costs low by avoiding any unnecessary storage. If you have configured your feature group as online-only, the latest values of a record override older values.
- Batch ingest into the offline store – You can choose to ingest data directly into your offline store. This is useful when you want to backfill historical records for training use cases. This can be done from SageMaker Data Wrangler or directly through a SageMaker Processing job Spark container. The offline store resides in your account and uses Amazon S3 to store data. This gives you the benefits of Amazon S3, including low cost of storage, durability, reliability and flexible access control. In addition, the feature group created in the offline store can be registered with appropriate metadata to provide support for search, discovery, and automatic creation of an AWS Glue Data Catalog.
- Batch ingest into both the online and offline store – If your feature group is configured to have both online and offline stores, you can do batch ingestion by calling the PutRecord API. In this case, only the latest values are stored in the online store, and the offline store maintains both your older records and the latest record. The offline store is an append-only data store.
To see an example of how you can couple streaming and batch feature engineering for an ML use-case, see Using streaming ingestion with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time.
Data Access
In this section, we discuss the details of real-time data access, access from the offline store, and advanced query patterns.
Real-time data access
SageMaker Feature Store provides a low latency GetRecord API, which is designed to serve real-time inference use cases. This is a synchronous API that provides strong read consistency and can be parallelized to support high-throughput applications. The GetRecord API lets you retrieve an entire record with all its features or a specific subset of features, which helps optimize access for shared feature groups with hundreds or thousands of features.
Data access from Offline Store
SageMaker Feature Store uses an S3 bucket in your account to store offline data. You can use query engines like Athena against the offline data store in Amazon S3 to analyze feature data or to join more than one feature group in a single query. SageMaker Feature Store automatically builds the AWS Glue Data Catalog for feature groups during feature group creation, and you can then use this catalog to access and query the data from the offline store using Athena or even open-source tools like Presto. You can set up an AWS Glue crawler to run on a schedule to make sure your catalog is always up to date. Because the offline store is in Amazon S3 in your account, you can use any of the capabilities that Amazon S3 provides, like replication.
For an example showing how you can run an Athena query on a dataset containing two feature groups using a Data Catalog that was built automatically, see Build Training Dataset. For detailed sample queries, see Athena and AWS Glue in Feature Store. These queries are also available in SageMaker Studio.
Advanced query patterns
The SageMaker Feature Store design allows you to access your data using advanced query patterns. For example, it’s easy to run a query against your offline store to see what your data looked like a month ago (time-travel). SageMaker Feature Store requires a parameter called EventTimeFeatureName in your feature group to store an event time for each record. This, combined with the append-only capability of the offline store, allows you to easily use query engines to get a snapshot of your data based on the event time feature. Other patterns include querying data after removing duplicates, reconstructing a dataset based on past events for training models, and gathering data needed for ensuring compliance with regulations.
We plan to publish a detailed post on how to use advanced query patterns (including time-travel) very soon.
Security: Encryption and access control
At AWS, we take data security very seriously, and as such, SageMaker Feature Store is architected to provide end-to-end encryption, fine-grained access control mechanisms, and the ability to set up private access via VPC.
Encryption at rest and in transit
After you ingest data, your data is always encrypted at rest and in transit. When you create a feature group for online or offline access, you can provide an AWS Key Management Service (AWS KMS) customer master key (CMK) to encrypt all your data at rest. If you don’t provide a CMK, we ensure that your data is encrypted on the server side using an AWS-managed CMK. We also support having different CMKs for online and offline stores.
Access control
SageMaker Feature Store lets you set up fine-grained access control to your data and APIs by using IAM user roles and policies to allow or deny specific actions. You can set up access control at the API or account level to enforce policies across all feature groups, or for individual feature groups. Creating, deleting, describing, and listing feature groups are all operations that can be managed by IAM policies. You can also set up private access to all operations in your app from your VPC via AWS PrivateLink.
Summary
At Amazon, customer obsession is in our DNA. We have spent countless hours listening to many customers and understanding their key pain points with managing features at an enterprise level for ML, and have used those requirements to develop SageMaker Feature Store.
SageMaker Feature Store is a purpose-built store that lets you define features one time for both large-scale offline model building and batch inference use cases, and also to get up to single-digit millisecond retrievals for real-time inference. You can easily name, organize, find, and share feature groups among teams of developers and data scientists—all from Amazon SageMaker Studio. SageMaker Feature Store offers feature consistency between training and inference by automatically replicating feature values from the online store to the historical offline store for model building. It’s tightly integrated with SageMaker Data Wrangler and SageMaker Pipelines to build repeatable feature engineering pipelines, but is also modular enough to easily integrate with your existing data processing and inferencing workflows. SageMaker Feature Store provides end-to-end encryption, secure data access, and API level controls to ensure that your data is adequately protected. For more information, see New – Store, Discover, and Share Machine Learning Features with Amazon SageMaker Feature Store.
We understand how crucial it is for you to get the right service guarantee in terms of running your mission critical applications on Amazon SageMaker Feature Store. Thus SageMaker Feature Store is backed by the same service assurances that AWS customers rely on AWS to provide.
About the Authors
 Lakshmi Ramakrishnan is a Principal Engineer at Amazon SageMaker Machine Learning (ML) platform team in AWS, providing technical leadership for the product. He has worked in several engineering roles in Amazon for over 9 years. He has a Bachelor of Engineering degree in Information Technology from National Institute of Technology, Karnataka, India and a Master of Science degree in Computer Science from the University of Minnesota Twin Cities.
Lakshmi Ramakrishnan is a Principal Engineer at Amazon SageMaker Machine Learning (ML) platform team in AWS, providing technical leadership for the product. He has worked in several engineering roles in Amazon for over 9 years. He has a Bachelor of Engineering degree in Information Technology from National Institute of Technology, Karnataka, India and a Master of Science degree in Computer Science from the University of Minnesota Twin Cities.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
 Ravi Khandelwal is a Software Dev Manager in Amazon SageMaker team leading engineering for SageMaker Feature Store. Prior to joining AWS, he has held engineering leadership roles in Amazon.com, FICO, and Thomson Reuters. He has an MBA from Carlson School of Management and an engineering degree from Indian Institute of Technology, Varanasi. He enjoys backpacking in the Pacific Northwest and is working towards a goal to hike in all US National Parks.
Ravi Khandelwal is a Software Dev Manager in Amazon SageMaker team leading engineering for SageMaker Feature Store. Prior to joining AWS, he has held engineering leadership roles in Amazon.com, FICO, and Thomson Reuters. He has an MBA from Carlson School of Management and an engineering degree from Indian Institute of Technology, Varanasi. He enjoys backpacking in the Pacific Northwest and is working towards a goal to hike in all US National Parks.
Dr. Romi Datta is a Principal Product Manager in Amazon SageMaker team responsible for training and feature store. He has been in AWS for over 2 years, holding several product management leadership roles in S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.