Amazon Web Services Feed
Working with timestamp with time zone in your Amazon S3-based data lake

With a data lake built on Amazon Simple Storage Service (Amazon S3), you can use the purpose-built analytics services for a range of use cases, from analyzing petabyte-scale datasets to querying the metadata of a single object. AWS analytics services support open file formats such as Parquet, ORC, JSON, Avro, CSV, and more, so it’s convenient to analyze with the tool that is most appropriate for your use case. For more information, see Amazon S3 as the Data Lake Storage Platform.
The TIMESTAMP and TIMESTAMPTZ (TIMESTAMP with time zone) data types are key data elements associated with many time-based datasets (for example clickstream, historical sales, and forecasting) in your data lake. But when you access the data across different analytical services, such as Amazon EMR-based ETL outputs being read by Amazon Redshift Spectrum, you may not know how the data will behave. Furthermore, lack of proper handling may cause accuracy issues in timestamp with time zone data types. This post delves into handling the TIMESTAMP and TIMESTAMPTZ data types in the context of a data lake by using a centralized data architecture. Because AWS analytical services cover a broad spectrum, we primarily focus on handing timestamps using Apache Hive, Apache Spark, Apache Parquet (using Amazon EMR and Amazon Athena), and Amazon Redshift to cover both the data lake and data warehouse.
Overview of TIMESTAMP and TIMESTAMPTZ data types in your data lake
Let’s start with some common definitions of the TIMESTAMP and TIMESTAMPTZ data types.
- The TIMESTAMP data type stores values that include the date and time of day. For example, 12/17/1997 17:37:16. Timestamps are presented without time zone information.
- The TIMESTAMPTZ data type to stores values with the date, time of day, and time zone. For example, 12/17/1997 17:37:16 (PST).
Internally, the timestamp is as an integer, representing seconds in UTC since the epoch (1970-01-01 00:00:00 UTC) and TIMESTAMPTZ values also stored as integers with respect to Coordinated Universal Time (UTC).
When working with the TIMESTAMPTZ data type, reads and writes use the time zone of the client user machine. When no time zone is set up or if left at the default values (such as the JVM/SQL client), it defaults to UTC.
Timestamp behavior when accessed across the analytical services
For this post, we discuss handling the timestamp with time zone data when accessed individually within the services and as well as between the services. The following diagram shows the architecture for this setup.

In this architecture, Parquet objects are stored in a centralized Amazon S3-based data lake, and Amazon EMR, Athena, and Amazon Redshift are used to access this centralized data. Data is also processed by these individual engines and accessed across these services through the Amazon S3 storage.
In this post, we illustrate the behavior of the different data types when data moves across different services from the Amazon S3 Parquet files.
Processing data in Amazon EMR (ETL) and accessing it with Amazon Redshift
In this use case, the Spark or Hive data pipeline generates Parquet files in the data lake and stores it in Amazon S3. Parquet files that are stored in Amazon S3 are loaded to Amazon Redshift using the COPY command. The following diagram illustrates this workflow.
To test this setup, complete the following steps:
- Create a Hive table and insert a sample row (for this post, we use an EMR cluster spun up in
us-west-2, PST):
- Verify the Parquet file content using the Parquet tool in Amazon S3:
In the preceding output, the Hive client running Amazon EMR interprets the time zone with respect to the end-user client (in PST), and converts it to UTC when writing to the Parquet file.
- Read through Hive and Spark (in Pacific time):
Amazon EMR Hive and Spark convert the underlying UTC stored timestamp values in Parquet to the client user machine’s relative time (PST) when displaying the results.
- Copy the Parquet file to an Amazon Redshift table with the TIMESTAMP column data type (in UTC). We use the SQL command line client tool psql to query the results in Amazon Redshift.
In the preceding output, the timestamp doesn’t have a time zone. All data is interpreted in UTC or whatever raw format it was when loaded into Amazon Redshift.
- Copy the Parquet file to the Amazon Redshift table using
TIMESTAMPTZ (UTC & Pacific):
The output shows that TIMESTAMPTZ can interpret the client time zone and convert the value with respect to the end-user client (PST), though the actual values are stored in UTC.
Processing data from Amazon Redshift and moving it to an Amazon S3 data lake
In the following use case, we copy data from Amazon Redshift to a data lake. Amazon Redshift stores the TIMESTAMP and TIMESTAMPTZ columns data types in a table. The table data is exported to Amazon S3 as Parquet files with the UNLOAD command. The following diagram illustrates this architecture.

To experiment with this setup, complete the following steps:
- Unload the Amazon Redshift table data to Amazon S3 (in UTC):
- Verify the Parquet file content:
- Create a table in Hive and query it (in UTC):
In the preceding output, the actual data in the Parquet file is stored in UTC, but Hive can read and display the local time zone using client settings.
When using Hive, set hive.parquet.timestamp.skip.conversion=false. Pre-3.1.2 Hive implementation of Parquet stores timestamps in UTC on-file; this flag allows you to skip the conversion when reading Parquet files created from other tools that may not have done so. Setting it to false treats legacy timestamps as UTC-normalized. For more information, see hive.parquet.timestamp.skip.conversion.
- Query using
Spark-SQL(in Pacific time):
In the preceding output, Spark converts the values with respect to the end-user client (PST), though the actual values are stored in UTC.
Accessing data through Athena
To access the data through Athena, you need to create the external table either in the AWS Glue Data Catalog or Hive metastore. In this example, we populate the Data Catalog.
To create a table using the Data Catalog, sign in to the Athena console and run the following DDL:
The following screenshot shows the query results.
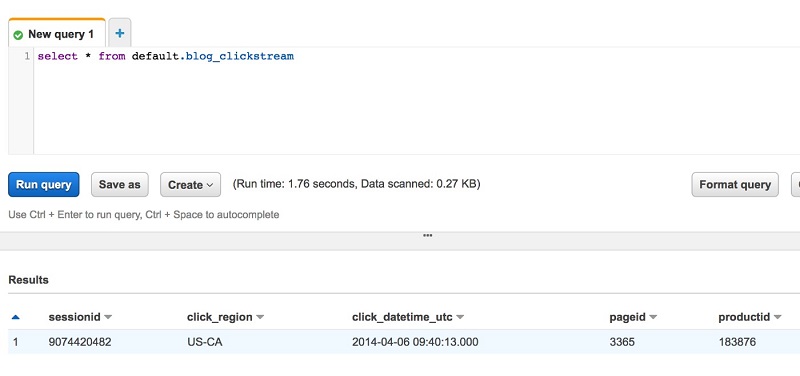
The results show that Athena converts click_datetime_utc to the user’s local time zone (in this case, PST).
Accessing data through Amazon Redshift Spectrum
To access the data through Amazon Redshift Spectrum, you need to create the following:
- The external database and table in the Data Catalog or a Hive metastore. We can use the same table we already created in the preceding use case (
default.blog_clickstream). - An Amazon Redshift external schema for the external database in the Data Catalog.
See the following code:
The output shows that Amazon Redshift Spectrum can convert click_datetime_utc to the local time zone of the user (PST).
Use cases for handling TIMESTAMP AND TIMESTAMPTZ data types
When implementing the data model for your data lake, the choice between selecting the TIMESTAMP or TIMESTAMPTZ data type depends on how your end-users consume the data. In this section, we discuss two different use cases.
Using TIMESTAMP for a uniform display of one normalized time
When you want a uniform display of a standard time (in a particular time zone), use the TIMESTAMP data type and baseline the values that are stored into a particular time zone. For example, the following table shows collected clickstream data from a global website.
| sessionid | click_region | click_datetime_utc | pageid | productid |
| 3682484416 | Chennai | 2014-04-06T 18:44:58 | 7156 | 309743 |
| 6367587374 | London | 2014-04-06T 18:44:58 | 5298 | 749625 |
| 9074420482 | Los Angles | 2014-04-06T 09:40:13 | 3365 | 183876 |
| 1746153004 | Perth | 2014-04-04T 06:13:28 | 3761 | 725195 |
| 1449344779 | Singapore | 2014-04-04T 06:13:28 | 3527 | 140229 |
| 4115543521 | New York | 2014-04-07T 09:22:28 | 3712 | 831655 |
| 2748081381 | Paris | 2014-04-07T 09:22:28 | 8474 | 347742 |
| 1120684200 | New York | 2014-04-07T 09:22:28 | 2731 | 568755 |
The clicks for the website come from users across the globe and are normalized for the UTC time zone using the click_datetime_utc column and a TIMESTAMP data type. You can accomplish this step during the data transformation process. Normalizing the data avoids confusion when data is analyzed across the different Regions without needing explicit conversion.
Using TIMESTAMPTZ for a contextual display of data depending on the user’s local time zone
When you need a contextual display of date and time for users accessing the data, choose the TIMESTAMPTZ data type. For example, let’s consider a customer service application that is accessing data from a centralized data warehouse. Individual users of the application are interested in analyzing data with respect which location the issue happened, rather than a normalized time zone. See the following code:
The following table summarizes the output.
| customer_id | customer_location | customer_timezone | issue_create_time | issue_create_time_utc | issue_id | issue_severity |
| 9589430063 | Chennai, India | IST | 4/5/2014 11:44:58 PM | 4/6/2014 04:44:58 AM | 2343 | 3 |
| 2796599493 | New York, US | EST | 4/6/2014 06:44:58 AM | 4/6/2014 11:44:58 AM | 2780 | 4 |
| 1836626118 | Toronto, CA | EDT | 4/4/2014 05:13:28 AM | 4/4/2014 10:13:28 AM | 7821 | 1 |
| 6790206978 | Sydney, Australia | AEDT | 4/5/2014 05:40:13 PM | 4/5/2014 10:40:13 PM | 3135 | 5 |
The issue_create_time column stores the date and time values and the time zone. When you query this table, you can view issue_create_time in your local time zone automatically (without any explicit conversion) by configuring set timezone or using a SQL client (such as SQL Workbench) that automatically adjusts this with respect your local computer settings.
In addition, you can also introduce optional redundant columns such as issue_create_time_utc for ease of use when users try to analyze the data across different Regions.
Independent of the approach taken for the implementation, there is no loss of timestamp or time zone values when using the preceding approach, and you can perform data aggregation on both columns without needing explicit conversion because all data is stored in UTC in the underlying storage (Parquet in Amazon Redshift). For example, you can roll up data into weekly or monthly aggregates across the Regions without any explicit conversion. The following example code calculates the weekly number of issues by priority across all locations:
Best practices for handling timestamps and time zones with data types
You should handle dates as either DATE, TIMESTAMP, or TIMESTAMPTZ data types and not convert them to strings. When dates are interpreted from strings, you lose all the features and flexiblity of working with date fields and date calculations, and also lose efficiency of processing. Moreover, casting or converting at runtime can be expensive.
When using TIMESTAMP or TIMESTAMPTZ data types, be aware of the client tools that access them. Client tool behavior largely depends on the local setting of the drivers and JVM. But it’s possible to override the behavior and always check for client tool-specific default behavior.
Use TIMESTAMPTZ only when absolutely necessary in the data model. In most use cases, TIMESTAMP simplifies data handling and avoids ambiguity when users access them.
Summary
In this post, we talked about handling and using TIMESTAMP and TIMESTAMPTZ data types with an Amazon S3-backed data lake. Most importantly, we covered how different AWS services like Amazon Redshift, Amazon EMR, Hive, and many other client tools interpret and interact with these data types. Choosing between using TIMESTAMP or TIMESTAMPTZ depends on the use case and how the end-user wants to visualize the data (a uniform display with one normalized time or a contextual display depending on time zone, respectively). Happy timestamping!
About the Authors
 Thiyagarajan Arumugam is a Principal Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
Thiyagarajan Arumugam is a Principal Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
 Srinivasan Krishnasamy is a ‘Senior Big Data Consultant’ at Amazon Web Services. He joined AWS in 2015 and specializes in building and supporting Big Data solutions that help customers to ingest, process and analyze data at scale.
Srinivasan Krishnasamy is a ‘Senior Big Data Consultant’ at Amazon Web Services. He joined AWS in 2015 and specializes in building and supporting Big Data solutions that help customers to ingest, process and analyze data at scale.
 Satish Sathiya is a Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.
Satish Sathiya is a Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.