Amazon Web Services Feed
Using Dremio for Fast and Easy Analysis of Amazon S3 Data

By Tomer Shiran, Chief Product Officer & Co-Founder at Dremio
By Shashi Raina, Partner Solution Architect at AWS
 |
 |
The infinite scalability, low cost, high availability (99.99% availability and 99.999999999% durability), and ease of administration of Amazon Simple Storage Service (Amazon S3) have made it the system of record in many organizations.
Werner Vogels, Chief Technology Officer at AWS, recently blogged about how the company built a strategic, company-wide data lake on Amazon S3 to break down silos and empower teams across the company to analyze data.
Thanks to the separation of storage, data, and compute, cloud data lakes are much more scalable and cost-efficient than data warehouses. However, they have not historically addressed the needs of business analysts.
Although many SQL engines allow business intelligence (BI) tools to query Amazon S3 data, organizations face multiple challenges, including high latency and infrastructure costs.
In this post, we explore how Dremio empowers analysts and data scientists to analyze data in S3 directly at interactive speed, without having to physically copy data into other systems or create extracts, cubes, and/or aggregation tables.
Dremio is an AWS Advanced Technology Partner that provides an analytics platform for business intelligence and data science workloads.
How Dremio Delivers Interactive-Speed SQL on Amazon S3
Dremio’s unique architecture enables faster and more reliable query performance than traditional SQL engines such as Presto and Apache Hive through a number of technology innovations.
The following table outlines some of the key architectural differences between Dremio and traditional query engines.
| Dremio | Other SQL Engines | |
| Engine architecture | Multiple engines (via elastic engines) | Single engine |
| In-memory data orientation | Columnar (via Apache Arrow) | Row-based |
| Execution kernel | Native (via Gandiva) | Java |
| Amazon S3 read latency | Accelerated (via Columnar Cloud Cache) | Normal |
| Query acceleration | Yes (via data reflections) | No |
| Client interfaces | ODBC, JDBC, and Arrow Flight | ODBC and JDBC only |
Elastic Engines
Dremio is an elastic, distributed system empowering BI users and data scientists to query Amazon S3 directly. To use Dremio, simply launch the Dremio coordinator Amazon Machine Instance (AMI) through AWS Marketplace, and either start a new project or open an existing one.
The Dremio coordinator automatically creates and manages additional Amazon Elastic Compute Cloud (Amazon EC2) instances serving as executors. The executors are organized in engines that can independently start and stop based on the workload.
Figure 1 shows an example of an AWS account with two Dremio deployments.
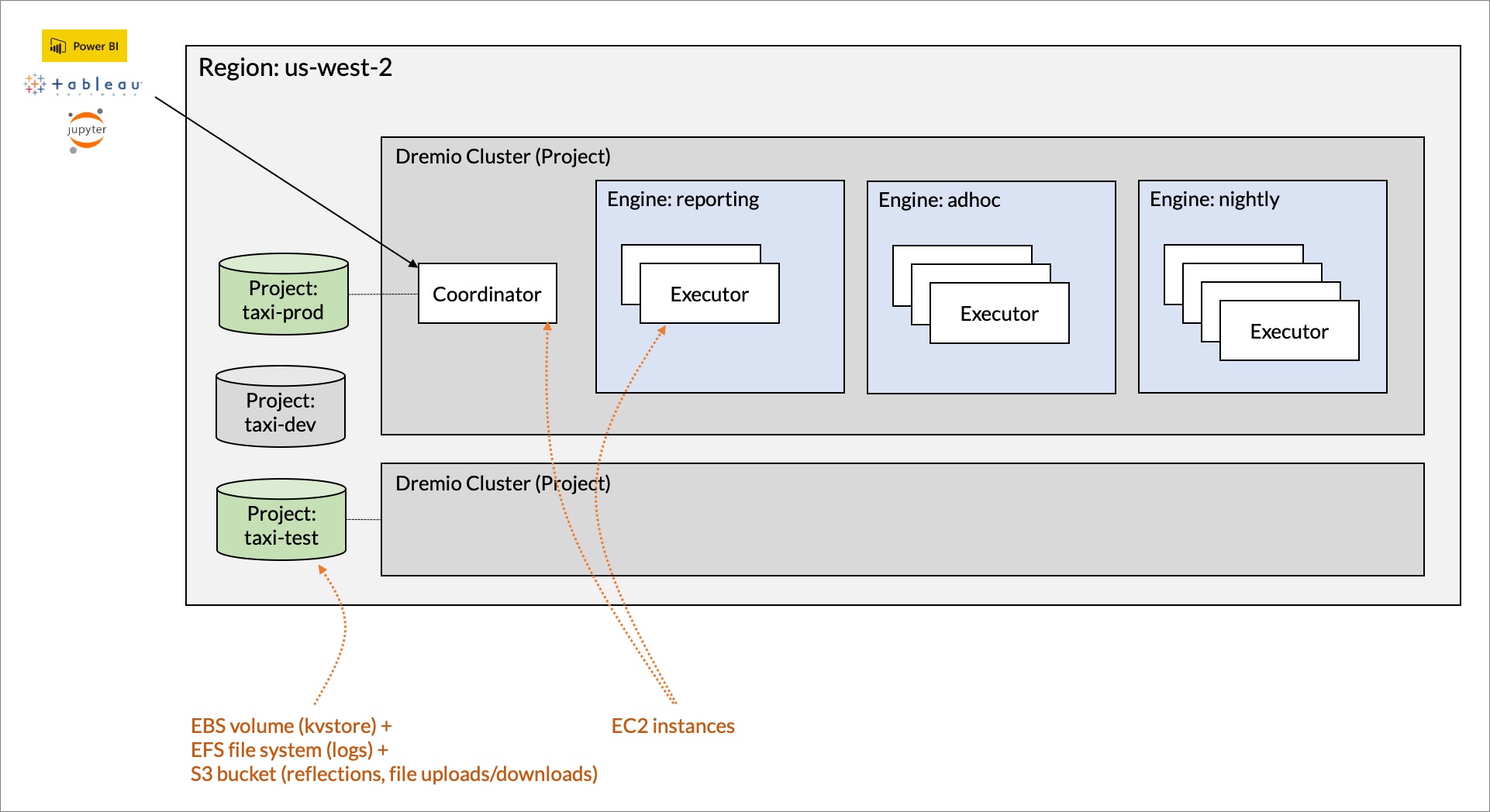
Figure 1 – AWS account with two Dremio deployments.
This example consists of two separate clusters (deployments). Each cluster is associated with a given project representing the state of the system. In this example, there are two active projects (taxi-prod and taxi-test), and one project (taxi-dev) that is not currently in use.
The multi-engine architecture of Dremio provides numerous benefits over traditional single-engine architectures:
- Cloud infrastructure costs are reduced by 60 percent or more (based on analysis of multiple workloads) because engines can be right-sized to the workload and automatically stop when not in use.
- The CPU, memory, and caching resources of one workload don’t impact another workload, making it possible to meet query performance SLAs.
- Time-sensitive, yet resource-intensive workloads (nightly jobs or reflections refreshes, for example) can be provisioned with the appropriate amount of resources to complete on time, but remain cost-effective by only running when required.
- It’s easy and inexpensive to experiment with different capacities. For example, it only takes a couple of minutes and mouse clicks to see how a query will perform on an xlarge engine, or a custom-sized engine with 20 c5d.18xlarge instances.
- Infrastructure costs can be allocated to teams by running their workloads on separate engines, enabling organizations to track and measure usage.
To view elastic engines defined in a cluster, select Elastic Engines in the Admin section.
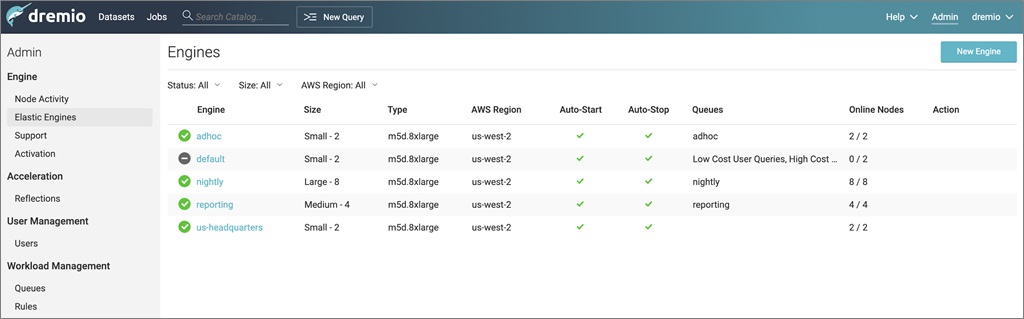
Figure 2 – Viewing the elastic engines defined in a cluster.
Apache Arrow, Gandiva, and Flight
Dremio created an open source project called Apache Arrow to provide industry-standard, columnar in-memory data representation. Arrow is currently downloaded over 10 million times per month, and is used by many open source and commercial technologies.
Dremio is based on Arrow internally. All data—as soon as it’s read from disk (on Parquet files, for example)—is represented in-memory in the columnar Arrow format.
All projections and filters in Dremio are executed by native code generated by Gandiva, an open source LLVM-based compiler that translates SQL expressions into vectorized execution kernels.
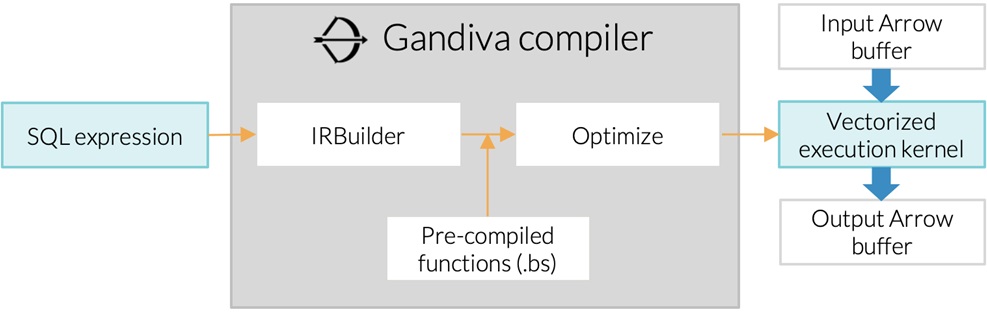
Figure 3 – All Dremio projections and filters are executed in Gandiva code.
For use cases in which large volumes of data must be returned to the client (to populate a Python data frame, for example), Dremio exposes an Arrow Flight interface that is 10-100x faster than ODBC and JDBC.
Arrow Flight-compatible clients, like Python and R, can consume query results directly from the Dremio engine. Because the Dremio engine represents data internally as Arrow buffers, it simply returns the final buffers to the client application without any row-by-row serialization or deserialization of data.
Columnar Cloud Cache
Cloud data lakes separate compute resources from data. The data is stored in open source formats in Amazon S3 where it can be accessed by a variety of services and technologies.
This is different from on-premises Hadoop data lakes, where compute and data were co-located, and from cloud data warehouses, where data is proprietary and can only be processed by one engine.
The Dremio columnar cloud cache feature takes advantage of the ephemeral NVMe storage on Amazon EC2 instances to cache data as it is read from S3. Thanks to columnar cloud cache, users can enjoy the scalability and low cost of S3, and the high performance of local NVMe.
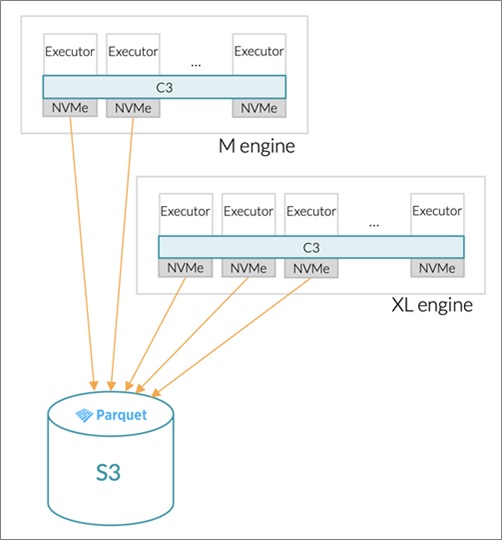
Figure 4 – Dremio columnar cloud cache.
Data Reflections
Even with Apache Arrow and columnar cloud cache, if the dataset is large or the query is complex, it may not be possible to achieve an interactive response time if the full table has to be scanned and the complex query has to be processed from scratch.
Dremio provides a solution for these situations called Data Reflections, which are optimized data structures that can accelerate query execution. Data reflections are typically used to materialize some common processing that occurs as part of a broader workload.
For example, if a workload consists of many queries on a join between datasets A and B, then it may make sense to materialize the join with a data reflection. Similarly, if Tableau or Power BI users will be interacting with dataset C, then it may make sense to materialize a pre-aggregation of this dataset with a data reflection.
Note that a single reflection can accelerate queries on many different virtual datasets.
Figure 5 shows the basic interface for creating a single aggregation reflection on a physical or virtual dataset in Dremio.

Figure 5 – Interface for creating a single aggregation reflection in Dremio.
For greater flexibility, an administrator can use the advanced mode (or the command line).
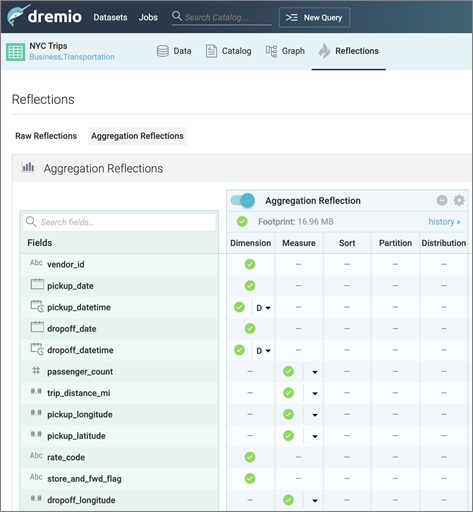
Figure 6 – Using the advanced mode for aggregation reflections.
Because data reflections are entirely transparent to the users querying the data, there’s no need to create any data reflections upfront. Instead, they can be created over time to address specific situations in which additional performance is needed.
This is in sharp contrast to traditional approaches to OLAP acceleration—cubes and aggregation tables, for example—in which the application (such as BI tool) must connect to a specific cube or aggregation table, and any changes are very costly and disruptive.
Managing Datasets in Dremio
In Dremio, you can manage physical datasets and virtual datasets.
Data Lake Tables (Physical Datasets)
Dremio supports several dataset representations/catalogs on Amazon S3:
- Files and Folders − Dremio enables users to treat a file or folder as a dataset. The folder is promoted to a dataset by selecting a button in the UI, or automatically by querying it. Once it’s considered a dataset, it is accessible through any client application such as Tableau or Power BI.
- Hive Metastore − Dremio supports Hive Metastore (2.x and 3.x). If users already have a Hive Metastore in their organization, they can simply add a Hive Metastore source in Dremio, and they can query those tables.
- AWS Glue − Dremio supports AWS Glue, a serverless catalog that is mostly compatible with Hive Metastore. If you’ve used AWS data services like AWS Lake Formation or Amazon Athena, you likely have an AWS Glue catalog in place already.
In addition to these catalogs, Dremio will soon support transactional table formats, including Apache Iceberg and Delta Lake.
The Semantic Layer (Virtual Datasets)
While data analysts need access to governed and curated datasets, that isn’t sufficient. Invariably, they also require the ability to derive their own datasets from those base datasets. This leads to a couple of challenges.
- First, many different copies/permutations are created (either all in the lake, or across multiple data stores). It quickly becomes impossible to keep these datasets in sync with each other.
- Many different models/views are created for different analyses, dashboards, and applications.
The sprawl of data and views ultimately results in inconsistent results and conclusions. The Dremio semantic layer, consisting of a well-organized virtual dataset repository backed by physical datasets and data reflections, enables data engineers and data consumers to overcome these challenges.
Figure 7 shows the top-level view of the semantic layer in Dremio. The virtual datasets are organized in spaces as well as sub-folders within those spaces.
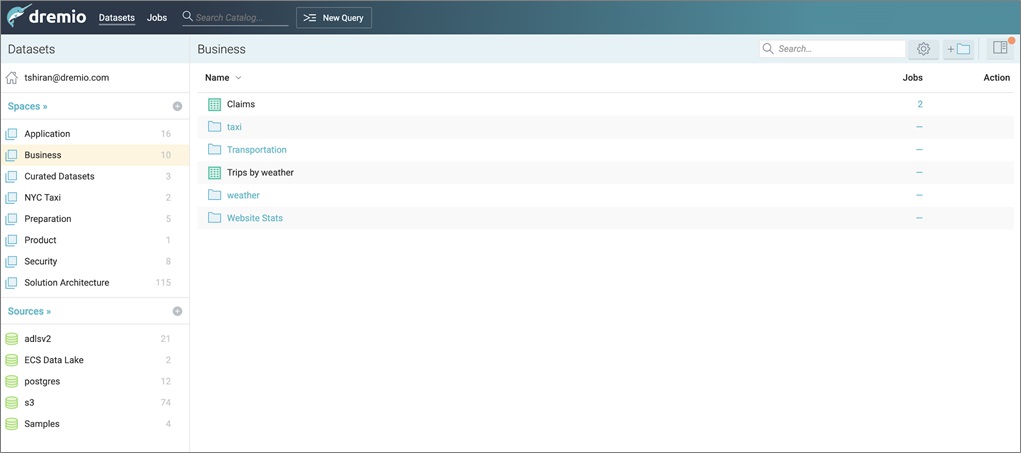
Figure 7 – Top-level view of the semantic layer in Dremio.
The semantic layer provides numerous benefits, including:
- Consistent business logic and KPIs across all users and client applications, such as Tableau, Power BI, Jupyter Notebooks, and even custom applications.
- Less reactive and tedious work to support data consumers. A semantic layer also makes it easy for the data team to quickly provision new virtual datasets to data consumers who do not have the knowledge or access to create them independently.
- Centralized data security and governance by using virtual datasets to provide different views of the data to different users and groups. For example, full-time data scientists may be allowed to see credit card numbers, but interns should see only the last four digits.
From “Zero to Query” in 5 Minutes
To deploy Dremio, follow these steps.
Step 1: Launch Dremio Through AWS Marketplace
Deploying Dremio in your AWS account is easy. Navigate to the Dremio listing in AWS Marketplace, and then follow the step-by-step instructions in the Dremio documentation to launch the coordinator and create your first project.
This process takes approximately five minutes to complete.
These are the typical steps for a simple environment:
- Use the provided AWS CloudFormation template to launch the coordinator.
. - Select Next, enter a Stack name, and then enter the desired parameters (VPC, Subnet, Allowed IP Range).
. - Select Next a couple more times, and then click Create Stack to launch the Dremio coordinator.
Figure 8 – Launching the Dremio coordinator.
- Within a couple of minutes, the status of the stack should change from CREATE_IN_PROGRESS to CREATE_COMPLETE.
. - Select the Outputs tab at the top, and then select one of the links to the Dremio UI (the public endpoint is more likely to be accessible from your client).
Figure 9 – Select one of the links to the Dremio UI.
- Select Authenticate, and then create your first project. Enter a name and accept the other settings.
. - Now, sit back and wait a few minutes while the coordinator creates the project resources and opens it.
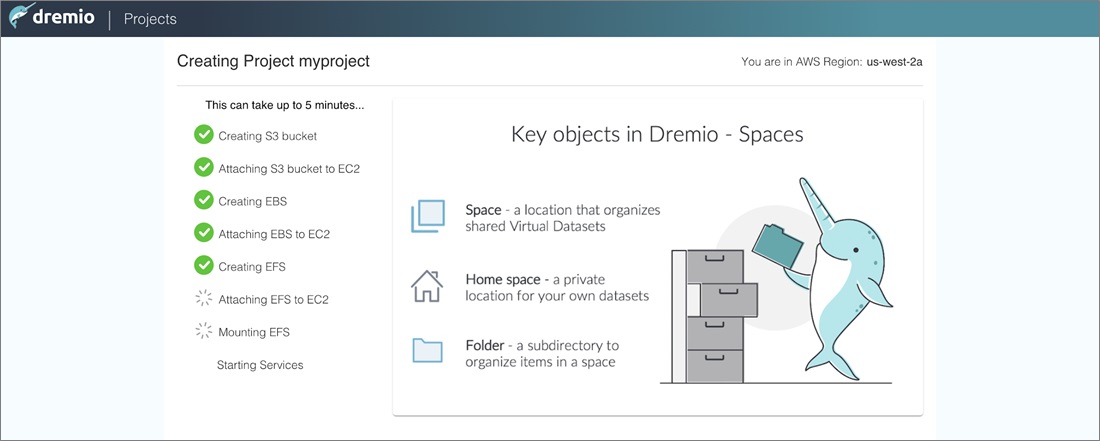
Figure 10 – Dremio creating a project.
- Once the project is ready, review the terms, and then create your initial user account in the project.
Query 1 Billion NYC Taxi Trips in Less Than a Second
Once you’ve launched Dremio, you can start using Dremio right away. However, if you’re not familiar with Dremio, we encourage you to select the Dremio Help button at the bottom of the screen, which gives you the opportunity to select an in-product tutorial to get started.
Note that you may need to refresh your browser to see the button. We recommend starting with the Tour of Dremio. Then, follow the tutorial Run My First Query, which guides you through how to run queries directly on data stored on Amazon S3. The tutorial demonstrates how to query a public dataset of over one billion New York City taxi trips in less than a second.
Case Study: InCrowd Sports
Hundreds of companies now rely on Dremio to enable interactive SQL and BI directly on Amazon S3. InCrowd Sports, a sports marketing company, is a great example of how high-performance analytics on S3 can significantly improve customer satisfaction and lead to new revenue opportunities.
InCrowd enables sports players, teams, and leagues to personalize the fan experience by connecting directly to their fans by analyzing a multitude of data sources, from ticketing data to clickstream and social data.
However, prior to implementing a new data architecture, the company was challenged by a slow and inflexible data warehouse, and it was finding it increasingly difficult to meet client expectations for immediate insights. Their architecture also did not provide the flexibility to easily add new data sources (clickstream data, for example), which resulted in missed opportunities for fan engagement and revenue.
To address these issues, InCrowd decided to implement a modern cloud architecture with Amazon S3 and the Dremio data lake engine. The Dremio self-service semantic layer, combined with lightning-fast queries directly on the massive amounts of data in S3, enables InCrowd to avoid a myriad of problems and costs associated with copying and moving significant volumes of their data into a proprietary data warehouse.
InCrowd is also able to access, curate, and query the vast majority of their data, versus only subsets that were available in a data warehouse.
With Dremio, InCrowd Sports is now able to provide its clients with faster, more secure access to more data, improving insights and fan experiences while reducing costs. Their clients can get one 360-degree view of how their fans are engaging, interacting, and spending across all digital and transactional touchpoints. Personalized analytics also enable them to provide a better fan experience and make targeted offers to increase revenue spend.
Conclusion
Dremio empowers analysts and data scientists to analyze data in Amazon S3 directly at interactive speed, without having to physically copy data into other systems or create extracts, cubes, and/or aggregation tables.
To learn more about Dremio, watch the recorded demonstration of the product. To try it out, choose Dremio (free) or Dremio Enterprise (on-demand pricing, includes enterprise security) on AWS Marketplace.
Follow the step-by-step instructions in the Dremio documentation to launch the coordinator and create your first project.
Data Lake Webinar on Nov. 10
To learn more about building a modern architecture for interactive analytics on an AWS data lake, check out this DBTA webinar on Nov. 10.
Experts from AWS and Dremio will discuss how to find the right balance between your data warehouse and data lake investments, and demonstrate how Dremio and AWS Glue make it possible to run BI workloads directly on Amazon S3.
.
.
Dremio – AWS Partner Spotlight
Dremio is an AWS Advanced Technology Partner that provides an analytics platform for business intelligence and data science workloads.
Contact Dremio | Practice Overview | AWS Marketplace
*Already worked with Dremio? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.