AWS Feed
Enable feature reuse across accounts and teams using Amazon SageMaker Feature Store

Amazon SageMaker Feature Store is a new capability of Amazon SageMaker that helps data scientists and machine learning (ML) engineers securely store, discover, and share curated data used in training and prediction workflows. As organizations build data-driven applications using ML, they’re constantly assembling and moving features between more and more functional teams. This constant movement of data can lead to inconsistencies in features and become a bottleneck when designing ML initiatives spanning multiple teams. For example, an ecommerce company might have several data science and engineering teams working on different aspects of their platform. The Core Search team focuses on query understanding and information retrieval tasks. The Product Success team solves problems involving customer reviews and feedback signals. The Personalization team uses clickstream and session data to create ML models for personalized recommendations. Additionally, data engineering teams like the Data Curation team can curate and validate user-specific information, which is an essential component that other teams can use. A Feature Store works as a unified interface between these teams, enabling one team to leverage the features generated by other teams, which minimizes the operational overhead of replicating and moving features across teams.
Training a production-ready ML model typically involves access to diverse set of features that aren’t always owned and maintained by the team that is building the model. A common practice for organizations that apply ML is to think of these data science teams as individual groups that work independently with limited collaboration. This results in ML workflows with no standardized way to share features across teams, which becomes a crucial limiting factor for data science productivity and makes it harder for data scientists to build new and complex models. With a shared feature store, organizations can achieve economies of scale. As more shared features become available, it becomes easier and cheaper for teams to build and maintain new models. These models can reuse features that are already developed, tested, and offered using a centralized feature store.
This post captures the essential cross-account architecture patterns for Feature Store that can be implemented in an organization with many data engineering and data science teams operating in different AWS accounts. We share how to enable sharing of features between accounts through a step-by-step example, which you can try out yourself with the code in our GitHub repo.
SageMaker Feature Store overview
By default, a SageMaker Feature Store is local to the account in which it is created, but it can also be centralized and shared by many accounts. An organization with multiple teams can have one centralized feature store that is shared across teams, as well as separate feature stores for use by individual teams. The separate stores can either hold feature groups that are of a sensitive nature or that are specific to a unique ML workload.
In this post, you first learn about the centralized feature store pattern. This pattern prescribes a central interface through which teams can create and publish new features, and from which other teams (or systems) can consume features. It also ensures that you have a single source of truth for feature data across your organization and simplifies resource management.
Next, you learn about the combined feature store pattern, which allows teams to maintain their own feature stores local to their account, while still being able to access shared features from the centralized feature store. These local feature stores are usually built for data science experimentation. By combining shared features from the centralized store with local features, teams can derive new enhanced features that can help when building more complex ML models. You can also use the local stores to store sensitive data that can’t be shared across the organization for regulatory and compliance reasons.
Lastly, we briefly cover a less common pattern involving replication of feature data.
Centralized feature store
Organizations can maximize the benefits of a feature store when it’s centralized. The centralized feature store pattern demonstrates how feature pipelines from multiple accounts can write to one centralized feature store, and how multiple other accounts can consume these features. This is a common pattern among mid- to large-sized enterprises where multiple teams manage different types of data or different parts of an application.
The process of hypothesizing, selecting, and transforming data inputs into a usable form suitable for ML models is called feature engineering. A feature pipeline encapsulates all the steps of the feature engineering process needed to convert raw data into useful features that ML models take as input for predictions. Maintaining feature pipelines is an expensive, time-consuming, and error-prone process. Also, replicating feature recipes and transformations across accounts can lead to inconsistencies and skew in feature characteristics. Because a centralized feature store facilitates knowledge sharing, teams don’t have to recreate feature recipes and rewrite pipelines from scratch in every project.
In this pattern, instead of writing features locally to an account-specific feature store, features are written to a centralized feature store. The centralized store serves as the central vault and creates a standardized way to access and maintain features for cross-team collaboration. It acts as an enabler and accelerator for AI adoption, reducing time to market for ML solutions, and allows for centralized governance and access control to ML features. You can grant access to external accounts, users, or roles to read and write individual feature groups in keeping with your data access policies. AWS recommends enforcing least privilege access to only the feature groups that you need for your job function. This is managed by the underlying AWS Identity and Access Management (IAM) policies. You can further refine access control with feature group tags and IAM conditions to decide which principals can perform specific actions. When you’re using a centralized store at scale, it’s important to also implement proper feature governance to ensure feature groups are well designed, have feature pipelines that are documented and supported, and have processes in place to ensure feature quality. This type of governance helps earn the trust required for feature reuse across teams.
Before walking through an example, let’s identify some key feature store concepts. First, feature groups are logical groups of features, typically originating from the same feature pipeline. An offline store contains large volumes of historical feature data used to create training and testing data for model development, or by batch applications for model scoring. The purpose of the online store is to serve these same features in real time with low latency. Unlike the offline store, which is append-only, the goal of the online store is to serve the most recent feature values. Behind the scenes, Feature Store automatically carries out data synchronization between the two stores. If you ingest new feature values into the online store, they’re automatically appended to the offline store. However, you can also create offline and online stores separately if this is a requirement for your team or project.
The following diagram depicts three functional teams, each with its own feature pipeline writing to a feature group in a centralized feature store.

The Personalization account manages user session data collected from a customer-facing application and owns a feature pipeline that produces a feature group called Sessions with features derived from the session data. This pipeline writes the generated feature values to the centralized feature store. Likewise, a feature pipeline in the Product Success account is responsible for producing features in the Reviews feature group, and the Data Curation account produces features in the Users feature group.
The centralized feature store account holds all features received from the three producer accounts, mapped to three feature groups: Sessions, Reviews, and Users. Feature pipelines can write to the centralized feature store by assuming a specific IAM role that is created in the centralized store account. We discuss how to enable this cross-account role later in this post. External accounts can also query features from the feature groups in the centralized store for training or inference, as shown in the preceding architecture diagram. For training, you can assume the IAM role from the centralized store and run cross-account Amazon Athena queries (as shown in the diagram), or initiate an Amazon EMR or SageMaker Processing job to create training datasets. In case of real-time inference, you can read online features directly via the same assumed IAM role for cross-account access.
In this model, the centralized feature store usually resides in a production account. Applications using this store can either live in this account or in other accounts with cross-account access to the centralized feature store. You can replicate this entire structure in lower environments, such as development or staging, for testing infrastructure changes before promoting them to production.
Combined feature store
In this section, we discuss a variant of the centralized feature store pattern called the combined feature store pattern. In feature engineering, a common practice is to combine existing features to derive new features. When teams combine shared features from the centralized store with local features in their own feature store, they can derive new enhanced features to help build more complex data models. We know from the previous section that the centralized store makes it easy for any data science team to access external features and use them with their existing pool of features to compound and evolve new features.
Security and compliance is another use case for teams to maintain a team-specific feature store in addition to accessing features from the centralized store. Many teams require specific access rights that aren’t granted to everyone in the organization. For example, it might not be feasible to publish features that are extracted from sensitive data to a centralized feature store within the organization.
In the following architecture diagram, the centralized feature store is the account that collects and catalogs all the features received from multiple feature pipelines into one central repository. In this example, the account of the combined store belongs to the Core Search team. This account is the consumer of the shareable features from the centralized store. In addition, this account manages user keyword data collected via a customer-facing search application.
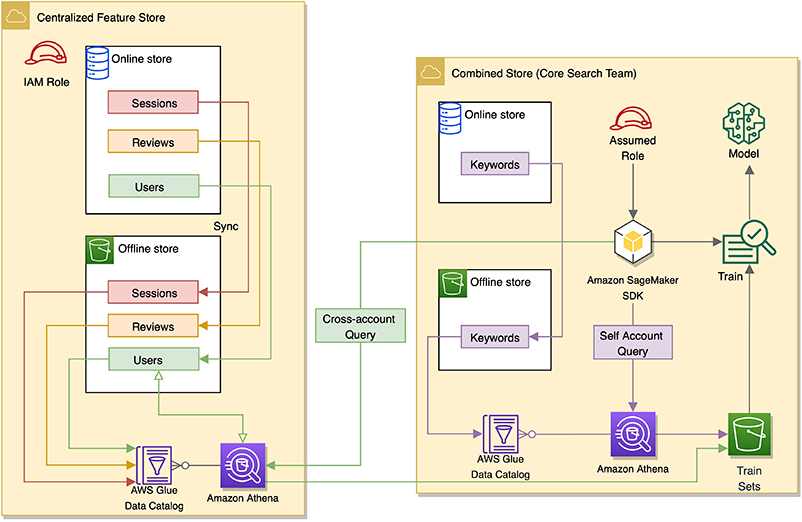
This account maintains its own local offline and online stores. These local stores are populated by a feature pipeline set up locally to ingest user query keyword data and generate features. These features are grouped under a feature group named Keywords. Feature Store by default automatically creates an AWS Glue table for this feature group, which is registered in the AWS Glue Data Catalog in this account. The metadata of this table points to the Amazon S3 location of the feature group in this account’s offline store.
The combined store account can also access feature groups Sessions, Reviews, and Users from the centralized store. You can enable cross-account access by role, which we discuss in the next sections. Data scientists and researchers can use Athena to query feature groups created locally and join these internal features with external features derived from the centralized store for data science experiments.
Cross-account access overview
This section provides an overview of how to enable cross-account access for Feature Store between two accounts using an assumed role via AWS Security Token Service (AWS STS). AWS STS is a web service that enables you to request temporary, limited-privilege credentials for IAM users. AWS STS returns a set of temporary security credentials that you can use to access AWS resources that you might not normally have access to. These temporary credentials consist of an access key ID, secret access key, and security token.
To demonstrate this process, assume we have two accounts, A and B, as shown in the following diagram.
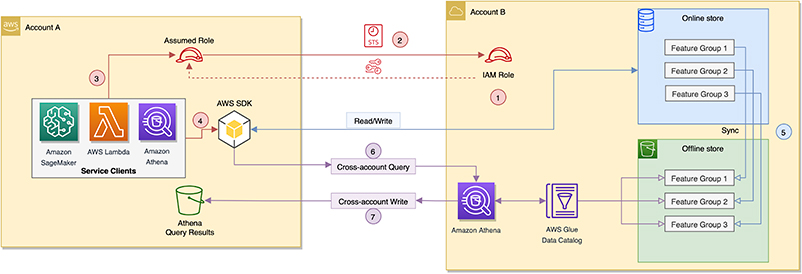
Account B maintains a centralized online and offline feature store. Account A needs access to both online and offline stores contained in Account B. To enable this, we create a role in Account B and let Account A assume that role using AWS STS. This enables Account A to behave like Account B, with permissions to perform specific actions identified by the role. AWS services like SageMaker (processing and training jobs, endpoints) and AWS Lambda used from Account A can assume the IAM role created in Account B by using an AWS STS client (see code block later in this post). This grants them the needed permissions to access resources like Amazon S3, Athena, and the AWS Glue Data Catalog inside Account B. After the services in Account A acquire the necessary permissions to the resources, they can access both the offline and online store in Account B. Depending on the choice of your service, you also need to add the IAM execution role for that service to the trusted policy of the cross-account IAM role in Account B. We discuss this in detail in the following section.
The preceding architecture diagram shows how Account A assumes a role from Account B to read and write to both online and offline stores contained within Account B. The seven steps in the diagram are as follows:
- Account B creates a role that can be assumed by others (for our use case, Account A).
- Account A assumes the IAM role from Account B using AWS STS. Account A can now generate temporary credentials that can be used to create AWS service clients that behave as if they are inside Account B.
- In Account A, SageMaker and other service clients (such as Amazon S3 and Athena) are created using the temporary credentials via the assumed role.
- The service clients in Account A can now create feature groups and populate feature values into Account B’s centralized online store using the AWS SDK.
- The online store in Account B automatically syncs with the offline store, also in Account B.
- The Athena service client inside Account A runs cross-account queries to read, group, and materialize feature sets using Athena tables inside Account B. Because the offline store exists in Account B, the corresponding AWS Glue tables, metadata catalog entries, and S3 objects all reside within Account B. Account A can use the AWS STS assume role to query the offline features (S3 objects) inside Account B.
- Athena query results are returned back as feature datasets into Account A’s S3 bucket.
The temporary credentials use the AWS STS GetSessionToken API and are limited to 1 hour. You can extend the duration of your session by using RefreshableCredentials, a Botocore class that can automatically refresh the credentials to work with your long-running applications beyond the 1-hour timeframe. An example notebook demonstrating this is available in our GitHub repo.
Create cross-account access
This section details all the steps to create the cross-account access roles, policies, and permissions to enable shareability of features between Accounts A and B according to our architecture.
Create a Feature Store access role
From Account B, we create a Feature Store access role. This is the role assumed by AWS services inside Account A to gain access to resources in Account B.
- On the IAM console, in the navigation pane, choose Roles.
- Choose Create role.
- Choose Another AWS account.
- For Account ID, enter the 12-digit account ID of Account B.
- Choose Next: Permissions.
- In the Permissions section, search for and attach the following AWS managed policies:
AmazonSageMakerFullAccess(you can further restrict this to least privileges based on your use case)AmazonSageMakerFeatureStoreAccess
- Create and attach a custom policy to this new role (provide the S3 bucket name in Account A where the Athena query results collected in Account B are written):
When you use this new AWS STS cross-account role from Account A, it can run Athena queries against the offline store content in Account B. The custom policy allows Athena (inside Account B) to write back the results to a results bucket in Account A. Make sure that this results bucket is created in Account A before you create the preceding policy.
Alternatively, you can let the centralized feature store in Account B maintain all the Athena query results in an S3 bucket. In this case, you have to set up cross-account Amazon S3 read access policies for external accounts to read the saved results (S3 objects).
- After you attach the policies, choose Next.
- Enter a name for this role (for example, cross-account-assume-role).
- On the Summary page for the created role, under Trust relationships, choose Edit trust relationship.
- Edit the access control policy document as shown in the following code:
The preceding code adds SageMaker and Athena as services in the Principal section. If you want more external accounts or roles to assume this role, you can add their corresponding ARNs in this section.
Create a SageMaker notebook instance
From Account A, create a SageMaker notebook instance with an IAM execution role. This role grants the SageMaker notebook in Account A the needed permissions to run actions on the feature store inside Account B. Alternatively, if you’re not using a SageMaker notebook and using Lambda instead, you need to create a role for Lambda with the same attached policies as shown in this section.
By default, the following policies are attached when you create a new execution role for a SageMaker notebook:
AmazonSageMaker-ExecutionPolicyAmazonSageMakerFullAccess

We need to create and attach two additional custom policies. First, create a custom policy with the following code, which allows the execution role in Account A to perform certain S3 actions needed to interact with the offline store in Account B:
You can also attach the AWS managed policy AmazonSageMakerFeatureStoreAccess, if your offline store S3 bucket name contains the SageMaker keyword.
Second, create the following custom policy, which allows the SageMaker notebook in Account A to assume the role (cross-account-assume-role) created in Account B:
We know Account A can access the online and offline store in Account B. When Account A assumes the cross-account AWS STS role of Account B, it can run Athena queries inside Account B against its offline store. However, the results of these queries (feature datasets) need to be saved in Account A’s S3 bucket in order to enable model training. Therefore, we need to create a bucket in Account A that can store the Athena query results as well as create a bucket policy (see the following code). This policy allows the cross-account AWS STS role to write and read objects in this bucket:
Modify the trust relationship policy
Because we created an IAM execution role in Account A, we use the ARN of this role to modify the trust relationships policy of the cross-account assume role in Account B:
Validate the setup process
After you set up all the roles and accompanying policies, you can validate the setup by running the example notebooks in the GitHub repo. The following code block is an excerpt from the example notebook and must be run in a SageMaker notebook running within Account A. It demonstrates how you can assume the cross-account role from Account B using AWS STS via the AssumeRole API call. This call returns a set of temporary credentials that Account A can use to create any service clients. When you use these clients, your code uses the permissions of the assumed role, and acts as if it belongs to Account B. For more information, see assume_role in the AWS SDK for Python (Boto 3) documentation.
After you create the SageMaker clients as per the preceding code example in Account A, you can create feature groups and populate features into Account B’s centralized online and offline store. For more information about how to create, describe, and delete feature groups, see create_feature_group in the Boto3 documentation. You can also use the Feature Store runtime client to put and get feature records to and from feature groups.
Offline store replication
Reproducibility is the ability to recreate an ML model exactly, so if you use the same features as input, the model returns the same output as the original model. This is essentially what we strive to achieve between the models we develop in a research environment and deploy in a production environment. Replicating feature engineering pipelines across accounts is a complex and time-consuming process that can introduce model discrepancies if not implemented properly. If the feature set used to train a model changes after the training phase, it may be difficult or impossible to reproduce a model.
Applications that reside on AWS usually have several distinct environments and accounts, such as development, testing, staging, and production. To achieve automated deployment of the application across different environments, we use CI/CD pipelines. Organizations often need to maintain isolated work environments and multiple copies of data in the same or different AWS Regions, or across different AWS accounts. In the context of Feature Store, some companies may want to replicate offline feature store data. Offline store replication via Amazon S3 replication can be a useful pattern in this case. This pattern enables isolated environments and accounts to retrain ML models using full feature sets without using cross-account roles or permissions.
Conclusion
In this post, we demonstrated various architecture patterns like the centralized feature store, combined feature store, and other design considerations for SageMaker Feature Store that are essential to cross-functional data science collaboration. We also showed how to set up cross-account access using AWS STS.
To learn more about Feature Store capabilities and use cases, see Understanding the key capabilities of Amazon SageMaker Feature Store and Using streaming ingestion with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time.
If you have any comments or questions, please leave them in the comments section.
About the Authors
 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds 6 AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds 6 AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.
 Stefan Natu is a Sr. AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.