AWS Feed
Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend
Many organizations spanning different sizes and industry verticals still rely on large volumes of documents to run their day-to-day operations. To solve this business challenge, customers are using intelligent document processing services from AWS such as Amazon Textract and Amazon Comprehend to help with extraction and process automation. Before you can extract text, key-value pairs, tables, and entities, you need to be able to split multipage PDF documents that often contain heterogeneous form types. For example, in mortgage processing, a broker or loan processing individual may need to split a consolidated PDF loan package, containing the mortgage application (Fannie Mae form 1003), W2s, income verification, 1040 tax forms, and more.
To tackle this problem, organizations use rules-based processing: identifying document types via form titles, page numbers, form lengths, and so on. These approaches are error-prone and difficult to scale, especially when the form types may have several variations. Accordingly, these workarounds break down quickly in practice and increase the need for human intervention.
In this post, we show how you can create your own document splitting solution with little code for any set of forms, without building custom rules or processing workflows.
Solution overview
For this post, we use a set of common mortgage application forms to demonstrate how you can use Amazon Textract and Amazon Comprehend to create an intelligent document splitter that is more robust than earlier approaches. When processing documents for mortgage applications, the borrower submits a multipage PDF that is made up of heterogeneous document types of varying page lengths; to extract information, the user (for example, a bank) must break down this PDF.
Although we show a specific example for mortgage forms, you can generally scale and apply this approach to just about any set of multi-page PDF documents.
We use Amazon Textract to extract data from the document and build an Amazon Comprehend compatible dataset to train a document classification model. Next, we train the classification model and create a classification endpoint that can perform real-time document analysis. Keep in mind that Amazon Textract and Amazon Comprehend classification endpoints incur charges, so refer to Amazon Textract pricing and Amazon Comprehend pricing for more information. Finally, we show how we can classify documents with this endpoint and split documents based on the classification results.
This solution uses the following AWS services:
- AWS CloudFormation
- Amazon Comprehend
- Amazon DynamoDB
- Elastic Load Balancing
- AWS Lambda
- Amazon Simple Storage Service (Amazon S3)
- AWS Step Functions
- Amazon Textract
Prerequisites
You need to complete the following prerequisites to build and deploy this solution:
- Install Python 3.8.x.
- Install jq.
- Install the AWS SAM CLI.
- Install Docker.
- Make sure you have pip installed.
- Install and configure the AWS Command Line Interface (AWS CLI).
- Configure your AWS credentials.
The solution is designed to work optimally in the us-east-1 and us-west-2 Regions to take advantage of higher default quotas for Amazon Textract. For specific Regional workloads, refer to Amazon Textract endpoints and quotas. Make sure you use a single Region for the entire solution.
Clone the repo
To get started, clone the repository by running the following command; then we switch into the working directory:
Solution workflows
The solution consists of three workflows:
- workflow1_endpointbuilder – Takes the training documents and builds a custom classification endpoint on Amazon Comprehend.
- workflow2_docsplitter – Acts as the document splitting service, where documents are split by class. It uses the classification endpoint created in
workflow1. - workflow3_local – Is intended for customers who are in highly regulated industries and can’t persist data in Amazon S3. This workflow contains local versions of
workflow1andworkflow2.
Let’s take a deep dive into each workflow and how they work.
Workflow 1: Build an Amazon Comprehend classifier from PDF, JPG, or PNG documents
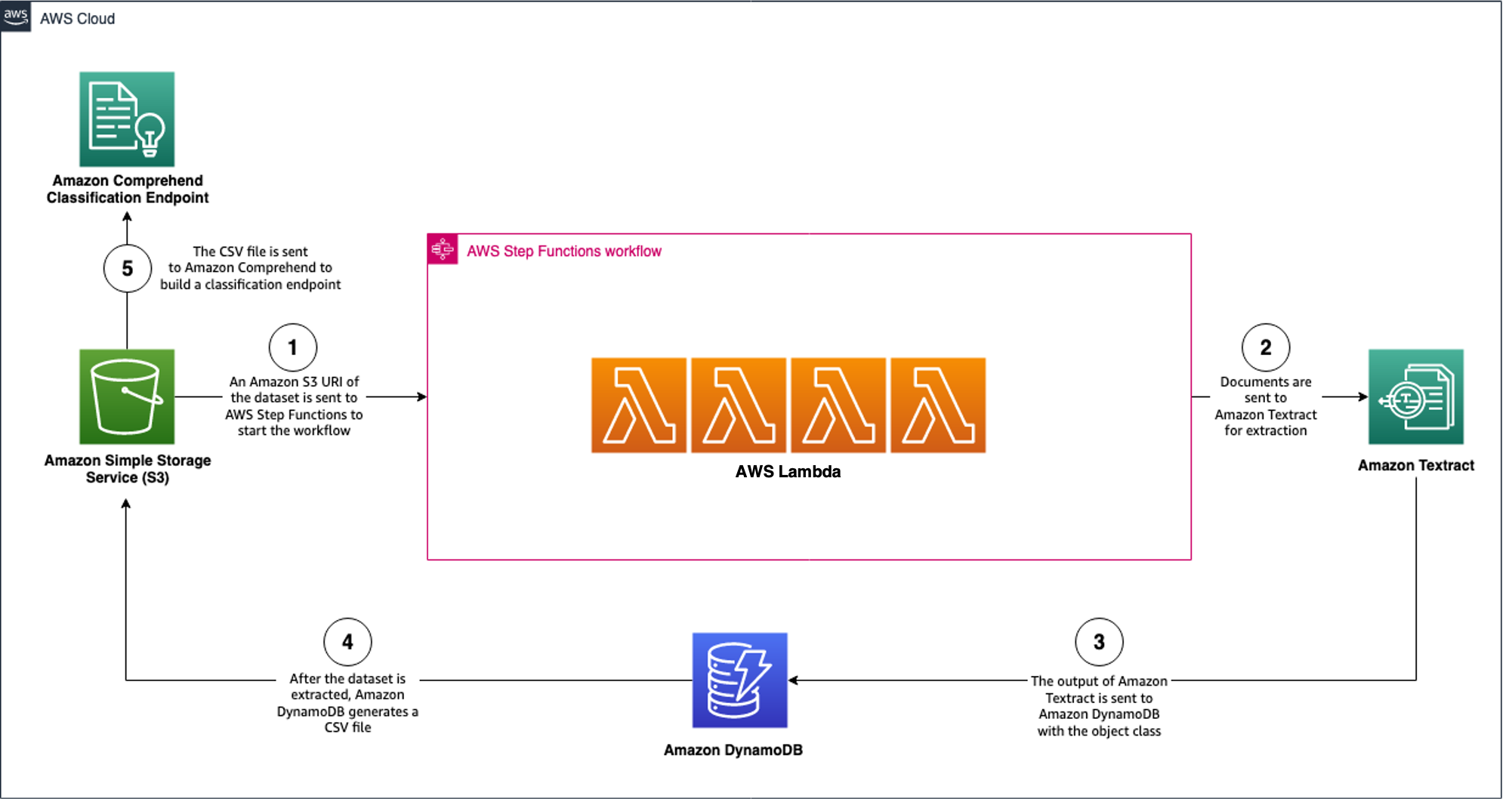
The first workflow takes documents stored on Amazon S3 and sends them through a series of steps to extract the data from the documents via Amazon Textract. Then, the extracted data is used to create an Amazon Comprehend custom classification endpoint. This is demonstrated in the following architecture diagram.
To launch workflow1, you need the Amazon S3 URI of the folder containing the training dataset files (these can be images, single-page PDFs, or multipage PDFs). The structure of the folder must be as follows:
Alternatively, the structure can have additional nested subdirectories:
The names of the class subdirectories (the second directory level) become the names of the classes used in the Amazon Comprehend custom classification model. For example, in the following file structure, the class for form123.pdf is tax_forms:
To launch the workflow, complete the following steps:
- Upload the dataset to an S3 bucket you own.
The recommendation is to have over 50 samples for each class you want to classify on. The following screenshot shows an example of this document class structure.

- Build the
sam-appby running the following commands (modify the provided commands as needed):
The output of the build is an ARN for a Step Functions state machine.
- When the build is complete, navigate to the State machines page on the Step Functions console.
- Choose the state machine you created.

- Choose Start execution.
- Enter the following required input parameters:
- Choose Start execution.

The state machine starts the workflow. This can take multiple hours depending on the size of the dataset. The following screenshot shows our state machine in progress.
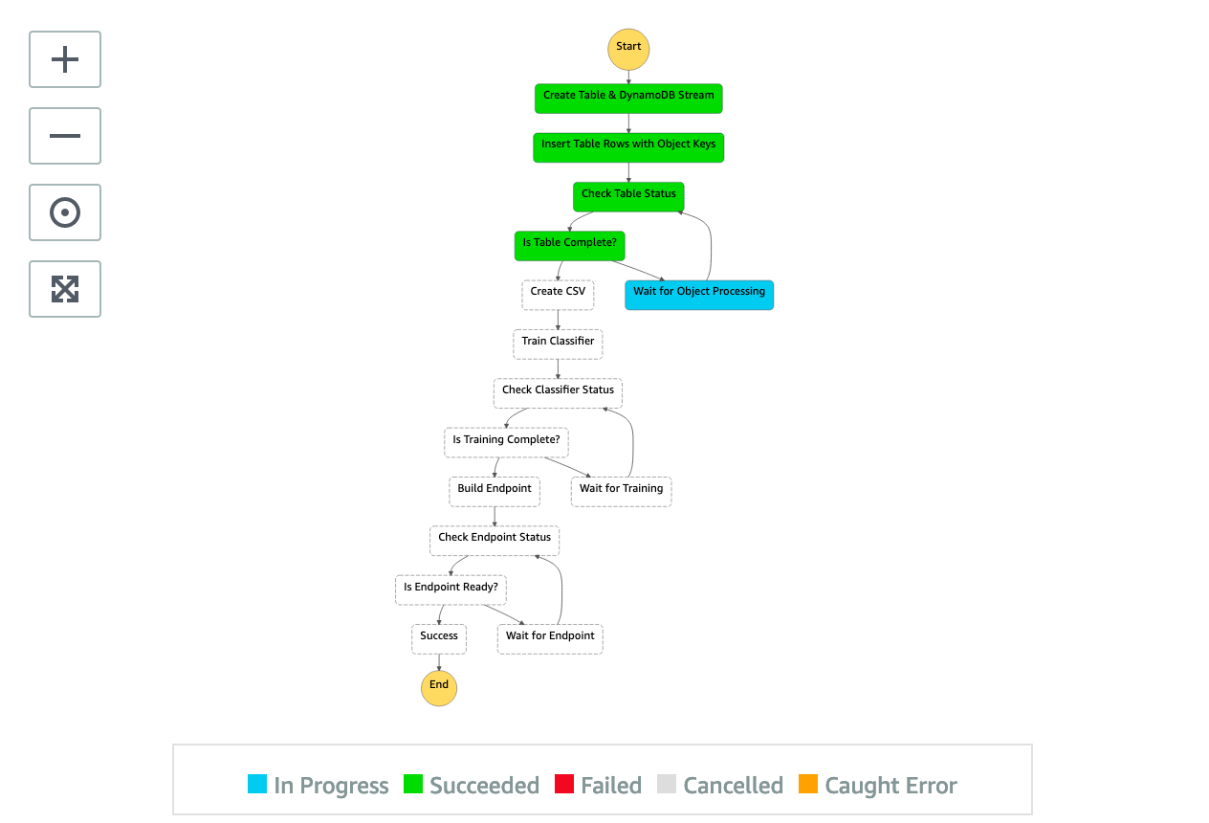
When the state machine is complete, each step in the graph is green, as shown in the following screenshot.

You can navigate to the Amazon Comprehend console to see the endpoint deployed.

You have now built your custom classifier using your documents. This marks the end of workflow1.
Workflow 2: Build an endpoint
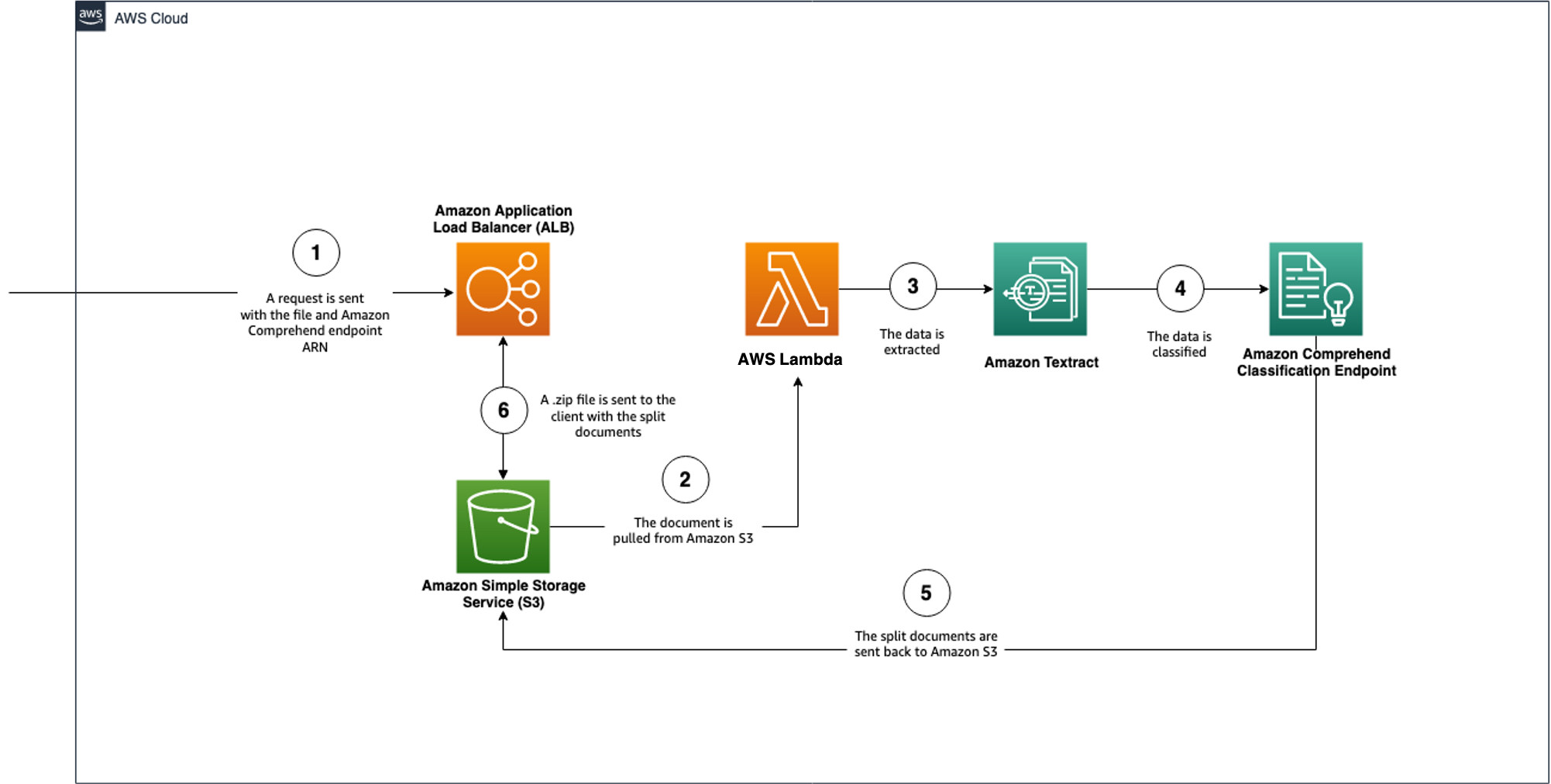
The second workflow takes the endpoint you created in workflow1 and splits the documents based on the classes with which model has been trained. This is demonstrated in the following architecture diagram.
To launch workflow2, we build the sam-app. Modify the provided commands as needed:
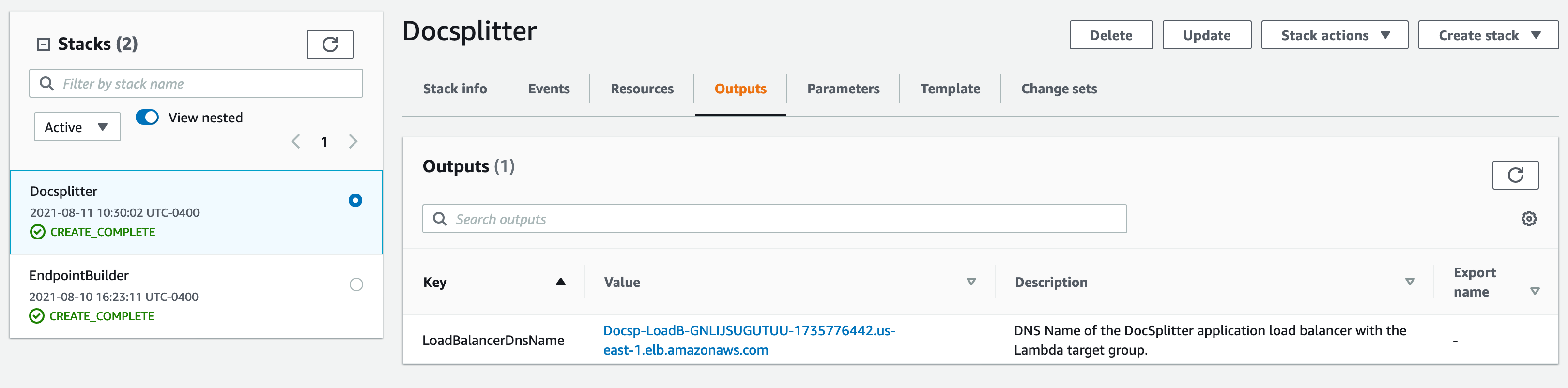
After the stack is created, you receive a Load Balancer DNS on the Outputs tab of the CloudFormation stack. You can begin to make requests to this endpoint.
A sample request is available in the workflow2_docsplitter/sample_request_folder/sample_s3_request.py file. The API takes three parameters: the S3 bucket name, the document Amazon S3 URI, and the Amazon Comprehend classification endpoint ARN. Workflow2 only supports PDF input.
For our test, we use an 11-page mortgage document with five different document types.






The response for the API is an Amazon S3 URI for a .zip file with all the split documents. You can also find this file in the bucket that you provided in your API call.
Download the object and review the documents split based on the class.

This marks the end of workflow2. We have now shown how we can use a custom Amazon Comprehend classification endpoint to classify and split documents.
Workflow 3: Local document splitting
Our third workflow follows a similar purpose to workflow1 and workflow2 to generate an Amazon Comprehend endpoint; however, all processing is done using the your local machine to generate an Amazon Comprehend compatible CSV file. This workflow was created for customers in highly regulated industries where persisting PDF documents on Amazon S3 may not be possible. The following architecture diagram is a visual representation of the local endpoint builder workflow.
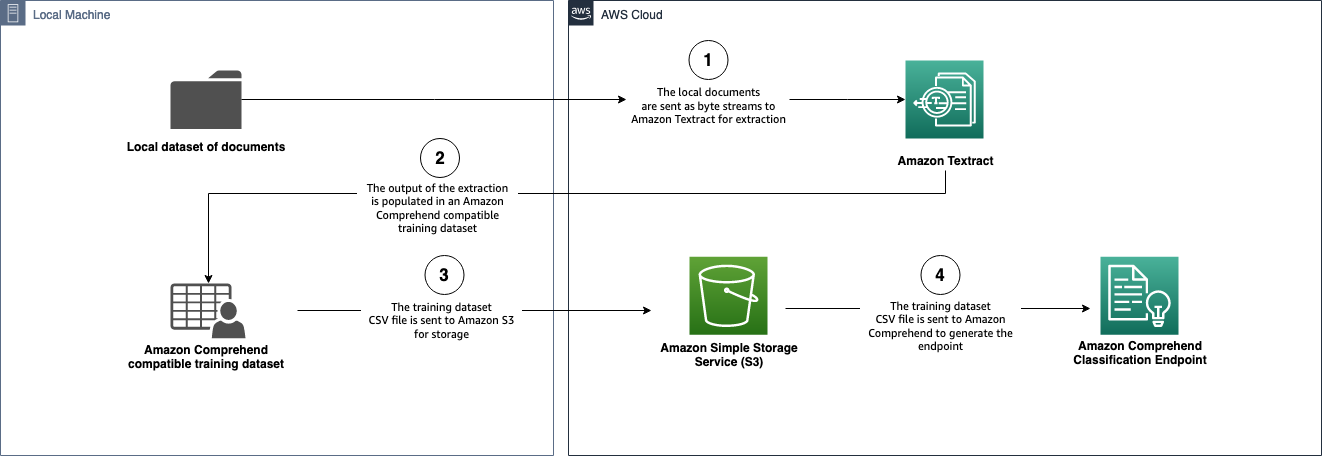
The following diagram illustrates the local document splitter architecture.

All the code for the solution is available in the workflow3_local/local_endpointbuilder.py file to build the Amazon Comprehend classification endpoint and workflow3_local/local_docsplitter.py to send documents for splitting.
Conclusion
Document splitting is the key to building a successful and intelligent document processing workflow. It is still a very relevant problem for businesses, especially organizations aggregating multiple document types for their day-to-day operations. Some examples include processing insurance claims documents, insurance policy applications, SEC documents, tax forms, and income verification forms.
In this post, we took a set of common documents used for loan processing, extracted the data using Amazon Textract, and built an Amazon Comprehend custom classification endpoint. With that endpoint, we classified incoming documents and split them based on their respective class. You can apply this process to nearly any set of documents with applications across a variety of industries, such as healthcare and financial services. To learn more about Amazon Textract, visit the webpage.
About the Authors
 Aditi Rajnish is a first-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
Aditi Rajnish is a first-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
 Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.