AWS Feed
Operating Lambda: Performance optimization – Part 1

In the Operating Lambda series, I cover important topics for developers, architects, and systems administrators who are managing AWS Lambda-based applications. This three-part series discusses performance optimization for Lambda-based applications.
Serverless applications can be extremely performant, thanks to the ease of parallelization and concurrency. While the Lambda service manages scaling automatically, you can optimize the individual Lambda functions used in your application to reduce latency and increase throughput.
This post describes the Lambda execution environment lifecycle, and explains defining, measuring, and improving cold starts.
Understanding cold starts and latency
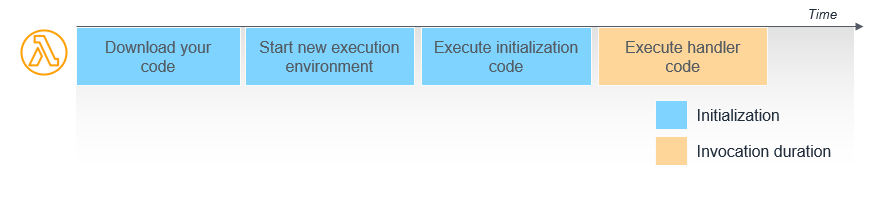
When the Lambda service receives a request to run a function via the Lambda API, the service first prepares an execution environment. During this step, the service downloads the code for the function, which is stored in an internal Amazon S3 bucket (or in Amazon Elastic Container Registry if the function uses container packaging). It then creates an environment with the memory, runtime, and configuration specified. Once complete, Lambda runs any initialization code outside of the event handler before finally running the handler code.

In this diagram, the first two steps of setting up the environment and the code are frequently referred to as a “cold start”. You are not charged for the time it takes for Lambda to prepare the function but it does add latency to the overall invocation duration.
After the execution completes, the execution environment is frozen. To improve resource management and performance, the Lambda service retains the execution environment for a non-deterministic period of time. During this time, if another request arrives for the same function, the service may reuse the environment. This second request typically finishes more quickly, since the execution environment already exists and it’s not necessary to download the code and run the initialization code. This is called a “warm start”.
According to an analysis of production Lambda workloads, cold starts typically occur in under 1% of invocations. The duration of a cold start varies from under 100 ms to over 1 second. Since the Lambda service optimizes internally based upon invocation patterns for functions, cold starts are typically more common in development and test functions than production workloads. This is because development and test functions are usually invoked less frequently. Overall, the Lambda service optimizes the execution of functions across all customers to reduce the number of cold starts.
The execution environment lifecycle
The Lambda service retains the execution environment instead of destroying it immediately after execution. The length of the environment’s lifetime is influenced by factors such as the amount of memory allocated to the function and the size of the code deployment package. The larger these resources, the longer the environment persists. There are also operational factors in the Lambda services that influence the retention time.
While execution environment reuse is useful, you should not depend on this for performance optimization. Lambda is a high availability service that manages execution across multiple Availability Zones in an AWS Region. Depending upon aggregate customer traffic, the service may load balance a function at any time. As a result, it’s possible for a function to be invoked twice in a short period of time, and both executions experience a cold-start due to this load rebalancing activity.
Additionally, in the event that a Lambda function scales up due to traffic, each additional concurrent invocation of the function requires a new execution environment. This means that each concurrent execution experiences a cold-start, even as existing concurrent functions may already be warm.
Finally, anytime you update the code in a Lambda function or change the functional configuration, the next invocation results in a cold start. Any existing environments running a previous version of the “Latest” alias are reaped to ensure that only the new version of the code is used.

Understanding how functions warmers work
The broader serverless community provides open source libraries to “warm” Lambda functions via a pinging mechanism. This approach uses EventBridge rules to schedule invocations of the function every minute to help keep the execution environment active. As a result, this can increase the likelihood of using a warm environment when you invoke the function.
However, this is not a guaranteed way to reduce cold starts. It does not help in production environments when functions scale up to meet traffic. It also does not work if the Lambda service runs your function in another Availability Zone as part of normal load-balancing operations. Additionally, the Lambda service reaps execution environments regularly to keep these fresh, so it’s possible to invoke a function in between pings. In all of these cases, you experience cold starts despite using a warming library. This approach might be adequate for development and test environments, or low-traffic or low-priority workloads.
Additionally, you cannot target a warm environment for an invocation. The Lambda service determines which execution environment receives a request based upon internal queueing and optimization factors. This is no affinity for repeat requests or any concept of “sticky sessions”, as may be set on traditional load balancers.
Reducing cold starts with Provisioned Concurrency
If you need predictable function start times for your workload, Provisioned Concurrency is the recommended solution to ensure the lowest possible latency. This feature keeps your functions initialized and warm, ready to respond in double-digit milliseconds at the scale you provision. Unlike on-demand Lambda functions, this means that all setup activities happen ahead of invocation, including running the initialization code.
For example, a function with a Provisioned Concurrency of 6 has 6 execution environments prepared ahead of when the invocations occur. In the time between initialization and invocation, the execution environment is prepared and ready.
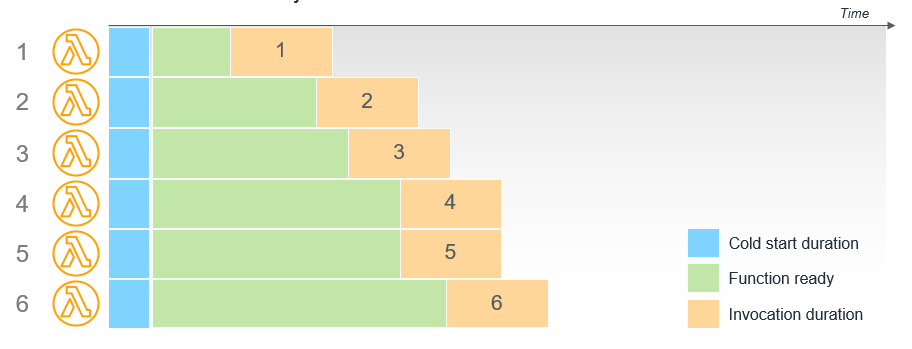
Functions with Provisioned Concurrency differ from on-demand functions in some important ways:
- Initialization code does not need to be optimized. Since this happens long before the invocation, lengthy initialization does not impact the latency of invocations. If you are using runtimes that typically take longer to initialize, like Java, the performance of these can benefit from using Provisioned Concurrency.
- Initialization code is run more frequently than the total number of invocations. Since Lambda is highly available, for every one unit of Provisioned Concurrency, there are a minimum of two execution environments prepared in separate Availability Zones. This is to ensure that your code is available in the event of a service disruption. As environments are reaped and load balancing occurs, Lambda over-provisions environments to ensure availability. You are not charged for this activity. If your code initializer implements logging, you will see additional log files anytime that this code is run, even though the main handler is not invoked.
- Provisioned Concurrency cannot be used with the $LATEST version. This feature can only be used with published versions and aliases of a function. If you see cold starts for functions configured to use Provisioned Concurrency, you may be invoking the $LATEST version, instead of the version or alias with Provisioned Concurrency configured.
Understanding invocation patterns
Lambda execution environments handle one request at a time. After the invocation has ended, the execution environment is retained for a period of time. If another request arrives, the environment is reused to handle the subsequent request.
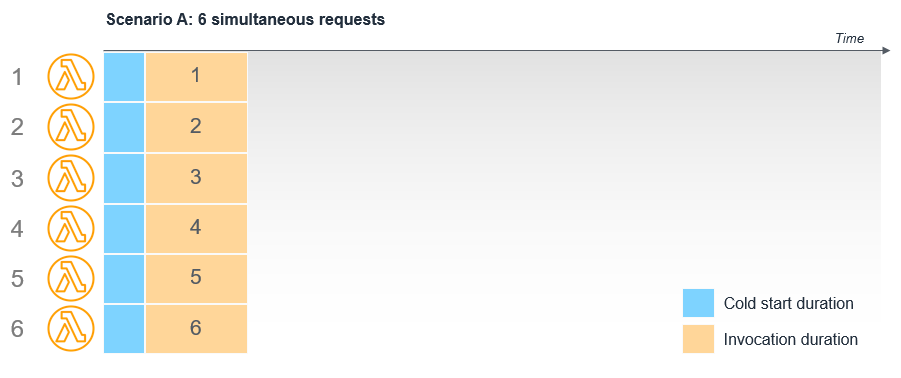
If requests arrive simultaneously, the Lambda service scales up the Lambda function to provide multiple execution environments. Each environment has to be set up independently, so each invocation experiences a full cold start.
For example, if Amazon API Gateway invokes a Lambda function six times simultaneously, this causes Lambda to create six execution environments. The total duration of each invocation includes a cold start:
However, if API Gateway invokes a Lambda function 6 times sequentially with a delay between each invocation, the existing execution environments are reused if the previous invocation is complete. In this case, only the first two invocations experience a cold start, while invocations 3 through 6 use warm environments:

For asynchronous invocations, an internal queue exists between the caller and the Lambda service. Lambda processes messages from this queue as quickly as possible and scales up automatically as needed. If the function uses reserved concurrency, this acts as a maximum capacity, so the internal queue retains the messages until the function can process them.
For example, an S3 bucket is configured to invoke a Lambda function when objects are written to the bucket:

If the reserved capacity of the Lambda function is set to 1 and 6 objects are written to the bucket simultaneously, the events are processed sequentially by a single execution environment. Pending events are maintained in the internal queue.
Conclusion
This post is the first in a 3-part series on performance optimization in Lambda. It explains how the Lambda execution environment works and why cold starts occur.
To minimize the latency in cold starts, I show how function warmers work and why Provisioned Concurrency is the preferred solution for production workloads. Finally, I explain invocation patterns and show several examples of how the invocation mode can impact invocation behavior and concurrency.
Part 2 will cover the effect of the memory configuration on Lambda performance, and how to optimize static initialization code.
For more serverless learning resources, visit Serverless Land.