Amazon Web Services Feed
Control data access and permissions with AWS Lake Formation and Amazon EMR

What if you could control the access to your data lake, centrally? Would it be more convenient to share specific data securely with internal and external customers?
With AWS Lake Formation and its integration with Amazon EMR, you can easily perform these administrative tasks.
This post goes through a use case and reviews the steps to control the data access and permissions of your existing data lake. Before you get started, review the following:
- Build, secure, and manage data lakes with AWS Lake Formation
- Creating a Data Lake from a JDBC Source in Lake Formation
Use case
Let’s assume your company has augmented their on-premises infrastructure with AWS. Because your data center has a fixed capacity for the company’s analytics and machine learning needs, you’re using the cloud for additional compute and storage. AWS Direct Connect links your data center to the closest AWS Region. Because your Active Directory server is still on premises, you use an Active Directory Connector to federate user authentication. For cost optimization and agility, you built a data lake to centralize business data to Amazon Simple Storage Service (Amazon S3) using Lake Formation.
Your organization is looking to improve their data analytics function and has hired external data analysis consultants. Based on the least privilege best practice, you want to only share the relevant data with the external consultants, without any personally identifiable information (PII) such as name, date of birth, and Social Security number.
You’re concerned about third-party data access in the cloud. You want a solution where the data is safe, controlled, audited, encrypted, and secure. You want to restrict access at the column level, so the PII isn’t available to the external consultants.
In addition, you want to restrict the consultants’ access to your cloud resource. They should only access the EMR cluster with a specific AWS Identity and Access Management (IAM) role.
The following diagram illustrates the architecture for this use case.
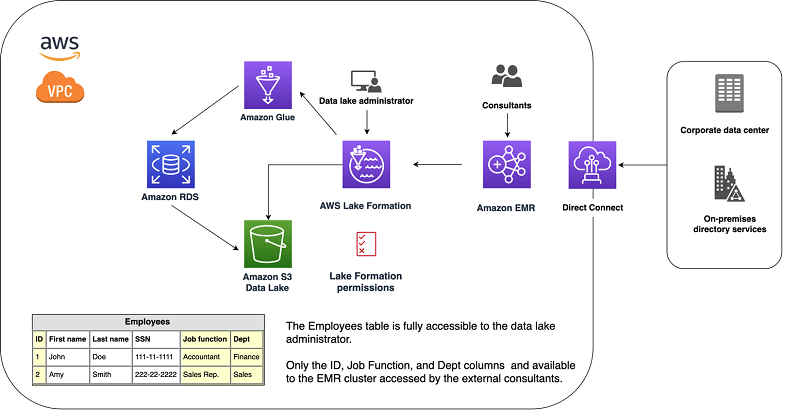
The external consultants authenticate the AWS resources against the on-premises, SAML-compatible directory service, federated with IAM. You control the access to the cloud resources from your on-premises identity provider (IdP). For more information, see About SAML 2.0-based Federation.
Lake Formation manages data access. The data lake administrator defines the data access at the column level for any principal defined in Lake Formation. The principal can be a user that you federate with the on-premises directory service. For this use case, the principal is a specific role for the external consultants that allows them to only access the EMR cluster.
Because you defined fine-grained Lake Formation permissions to your data, the external consultants can’t access employee first names, last names, and Social Security numbers. They only have access to the non-PII columns. This measure is called pseudonymization, in which you can’t identify the PII without additional data. Pseudonymization has the following benefits:
- Centralized authentication and user and data access governance
- Less management overhead and security improvement because there is a canonical source of authentication
- The consultant uses an IAM role allowing only Lake Formation data access and the instance profile role associated with the EMR cluster
You don’t need to manage access to Amazon S3; access is centralized from Lake Formation. If you want to share the data lake data with more users, you only need to define it one time in Lake Formation.
In the next section, you see how to implement this solution.
Creating a data lake
Before you get started, create a data lake. You can control the access to the data lake with policies and permissions, and define permissions at the database, table, or column level.
When creating the database, complete the following steps to enable fine-grained access control with Lake Formation permissions.
- On the Lake Formation console, under Data catalog, choose Databases.
- Choose Create database.

- For Name, enter a name for your database.
- Deselect Use only IAM access control for new tables in this database.
This step enables fine-grained access control with Lake Formation permissions.
- Choose Create database.

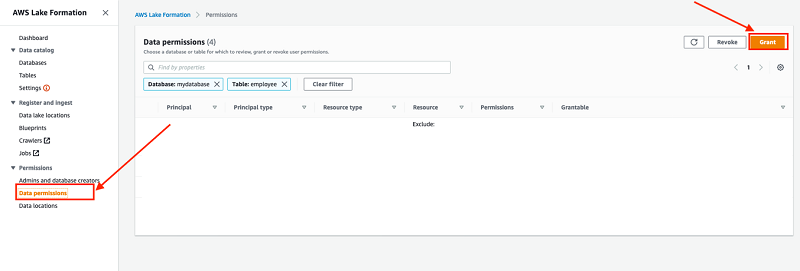
Adjusting the permissions
- Under Permissions, choose Data permissions.
- Choose Grant.
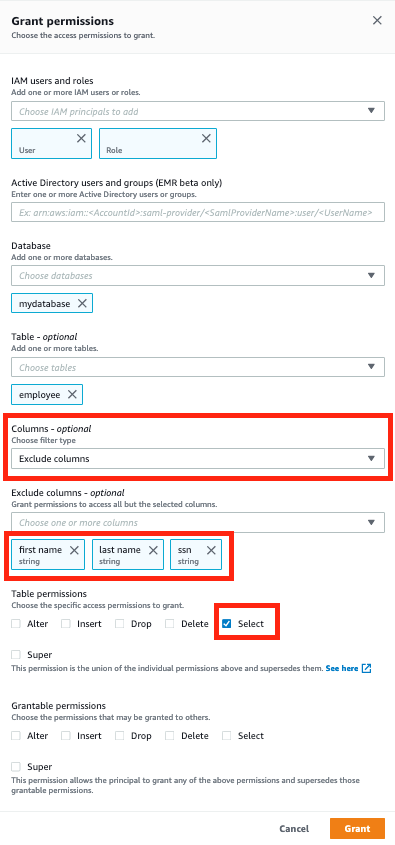
- For IAM users and roles, choose which specific IAM users and roles can access the data lake.
These accounts can be federated with your SAML 2.0 compatible IdP with AWS, so you can control the access from your on-premises Active Directory.
You can also define Active Directory users and groups directly, but only in the context of Amazon EMR integration with Lake Formation. For more information, see Amazon EMR Integration With AWS Lake Formation Is Now In Beta, Supporting Database, Table, and Column-level access controls for Apache Spark and Amazon EMR Components.
- For Database, choose your database.
- For Table, choose your table.
- For Columns, choose Exclude columns.
- For Exclude columns, choose which columns to exclude (for this use case, first name, last name, and ssn).
- For Table permissions, select Select.
This feature allows you to control column-level access for an IAM user or a role.
- Choose Grant.
Integrating Lake Formation with Amazon EMR
From Amazon EMR version 5.26 onwards, you can launch an EMR cluster that integrates with Lake Formation. Amazon EMR can only access specific columns or data based on the permissions defined in Lake Formation. For more information, see Architecture of SAML-Enabled Single Sign-On and Fine-Grained Access Control.
A key requirement is to have an external IdP, such as Microsoft Active Directory, Okta, or Auth0, defined for the EMR cluster. The benefit is that you can use your existing enterprise directory, compliance, and audits to govern the data access to Lake Formation. For instructions, see Integrating Amazon EMR with AWS Lake Formation (Beta).
When integration is complete, the consultants can consume the data from Amazon EMR via Zeppelin or Apache Spark, without accessing the PII.
Additional security measures
As with most AWS services, Amazon EMR and Lake Formation use IAM features. With IAM, you can define IAM users or roles to grant access to other AWS services and data.
On top of this security model, AWS CloudTrail tracks all AWS API requests. You can use this audit trail for governance and compliance purposes because you can trace all usage of AWS resources.
To protect the data, you can use in-transit and at-rest encryption. You can also define specific security configurations to apply to your EMR cluster. For more information, see Encryption Options.
For additional security services, you can use Amazon GuardDuty (a threat detection service) and Amazon Macie (data discovery and protection at scale). For more information, see Security, Identity, and Compliance on AWS.
Conclusion
Data usage has grown rapidly in terms of formats and sizes. Managing different technologies (relational databases, NoSQL, Graph, flat files, and more) adds management overhead and costs. Due to constant competition, as data size soars with compute and storage needs, organizations require more agility and speed.
In addition, you may be sharing business needs data with more internal and external customers. This causes increasing complexity in data governance and additional burdens in permission and access management.
In this post, we explained how you can control the access and permission of your data lake. AWS allows you to support your organization’s growth and security because data access is controlled, encrypted, and audited. This is possible in the context of a hybrid infrastructure with an on-premises IdP controlling access to AWS and other resources.
You can start your data lake project and share data with different roles in your organization in a scalable and secure way. It takes minutes instead of months, without mobilizing an important engineering footprint.
As a next step, you can use the curated data as the foundation for machine learning projects with AWS Machine Learning tools.
About the Authors
 Nabil Ezzarhouni is a Partner Solutions Architect with AWS. His interests are DevOps, Machine Learning and his dog Bandit (he’s a born-again pet lover).
Nabil Ezzarhouni is a Partner Solutions Architect with AWS. His interests are DevOps, Machine Learning and his dog Bandit (he’s a born-again pet lover).
Pawan Matta is a Solutions Architect with AWS. Pawan enjoys working with customers and helping them in area of Storage and Migration. During his free time, Pawan loves spending time watching cricket and playing video games with friends