Amazon Web Services Feed
New – Label 3D Point Clouds with Amazon SageMaker Ground Truth
Launched at AWS re:Invent 2018, Amazon Sagemaker Ground Truth is a capability of Amazon SageMaker that makes it easy to annotate machine learning datasets. Customers can efficiently and accurately label image and text data with built-in workflows, or any other type of data with custom workflows. Data samples are automatically distributed to a workforce (private, 3rd party or MTurk), and annotations are stored in Amazon Simple Storage Service (S3). Optionally, automated data labeling may also be enabled, reducing both the amount of time required to label the dataset, and the associated costs.
About a year ago, I met with Automotive customers who expressed interest in labeling 3-dimensional (3D) datasets for autonomous driving. Captured by LIDAR sensors, these datasets are particularly large and complex. Data is stored in frames that typically contain 50,000 to 5 million points, and can weigh up to hundreds of Megabytes each. Frames are either stored individually, or in sequences that make it easier to track moving objects.
As you can imagine, labeling these datasets is extremely time-consuming, as workers need to navigate complex 3D scenes and annotate many different object classes. This often requires building and managing very complex tools. Always looking to help customers build simpler and more efficient workflows, the Ground Truth team gathered more feedback, and got to work.
Today, I’m extremely happy to announce that you can use Amazon Sagemaker Ground Truth to label 3D point clouds using a built-in editor, and state-of-the-art assistive labeling features.
Introducing 3D Point Cloud Labeling
Just like for other Ground Truth tasks types, input data for 3D point clouds has to be stored in an S3 bucket. It also needs to be described by a manifest file, a JSON file containing both the location of frames in S3 and their attributes. A dataset may contain either single-frame data, or multi-frame sequences.
Optionally, the dataset may also include image data captured by on-board cameras. Using a feature called “sensor fusion”, Ground Truth can synchronize a 3D point cloud with up to 8 cameras. Thanks to this, workers get a real-life view of the scene, and they can also interchangeably apply labels to 2D images and 3D point clouds.
Once the manifest file is ready, Ground Truth lets you create the following task types:
- Object Detection: identify objects of interest within a 3D point cloud frame.
- Object Tracking: track objects of interest across a sequence of 3D point cloud frames.
- Semantic Segmentation: segment the points of a 3D point cloud frame into predefined categories.
These can either be labeling jobs where workers annotate new frames, or adjustment jobs where they review and fine-tune existing annotations. Jobs may be distributed either to a private workforce or to a vendor workforce you picked on AWS Marketplace.
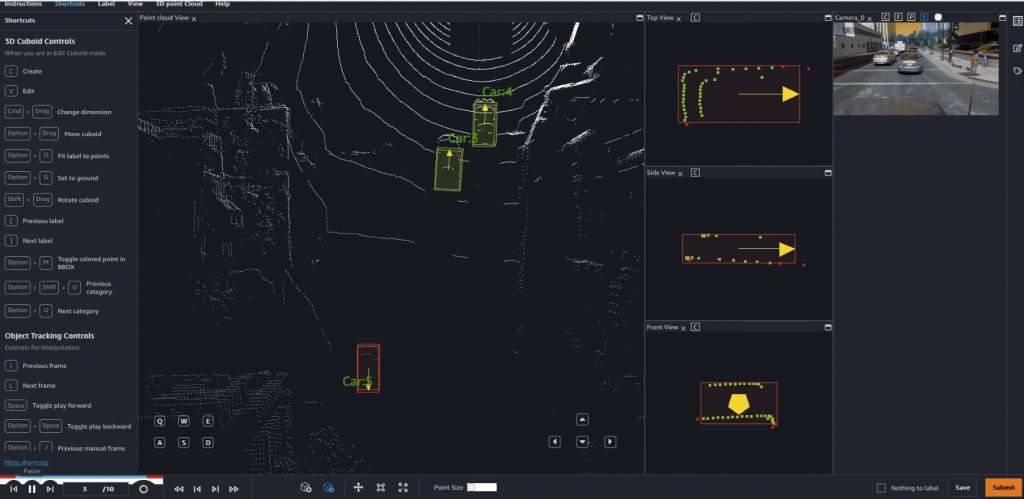
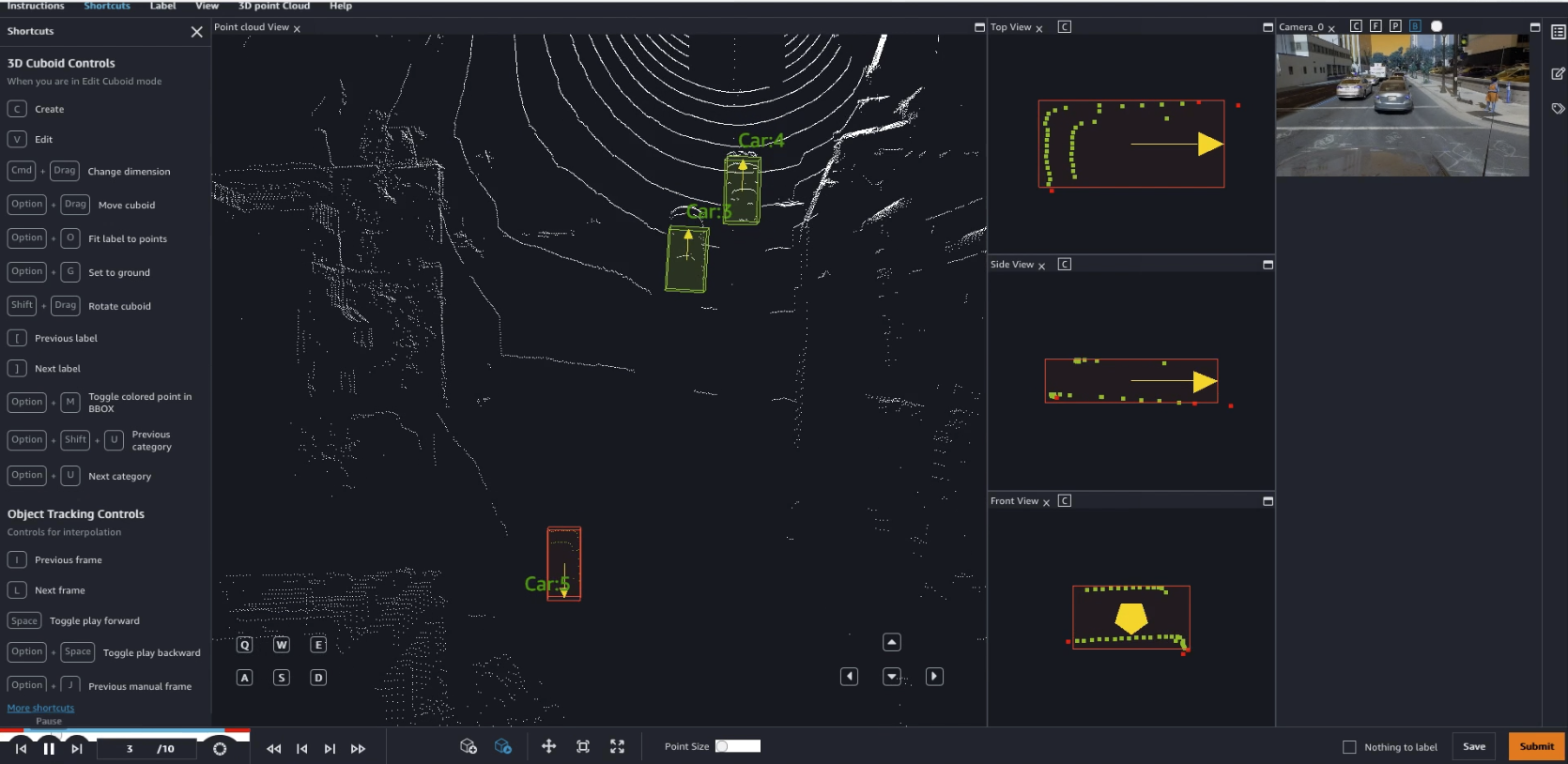
Using the built-in graphical user interface (GUI) and its shortcuts for navigation and labeling, workers can quickly and accurately apply labels, boxes and categories to 3D objects (“car”, “pedestrian”, and so on). They can also add user-defined attributes, such as the color of a car, or whether an object is fully or partially visible.
The GUI includes many assistive labeling features that significantly simplify labeling work, save time, and improve the quality of annotations. Here are a few examples:
- Snapping: Ground Truth infers a tight-fitting box around the object.
- Interpolation: the labeler annotates an object in the first and last frames of a sequence. Ground Truth automatically annotates it in the middle frames.
- Ground detection and removal: Ground Truth can automatically detect and remove 3D points belonging to the ground from object boxes.
Even with assistive labeling, it may take a while to annotate complex frames and sequences, so work is saved periodically to avoid any data loss.
Preparing 3D Point Cloud Datasets
As previously mentioned, you have to provide a manifest file describing your 3D dataset. The format of this file is defined in the Ground Truth documentation. Of course, the steps required to build it will vary from one dataset to the next. For example, the Audi A2D2 dataset contains almost 400,000 frames, with 360-degree 3D LIDAR data and 2D images. KITTI, another popular choice for autonomous driving research, includes a 3D dataset with 15,000 images and their corresponding point clouds, for a total of 80,256 labeled objects. This notebook shows you how to convert KITTI data to the Ground Truth format.
When datasets contain both 3D LIDAR data and 2D camera images, one challenge is to synchronize them. This allows us to project 3D points to 2D coordinates, map them on the pictures captured by on-board cameras, and vice versa. Another challenge is that data captured by a given device uses coordinates local to this device. Fortunately, we know where the device is located on the car, and where it’s pointed to. All of this can be solved by building a global coordinate system, also known as a World Coordinate System (WCS). Using matrix operations (which I’ll spare you), we can compute the coordinates of all data points inside the WCS.
Once frames have been processed, their information is saved in the manifest file: the position of the vehicle, the location of LIDAR data in S3, the location of associated pictures in S3, and so on. For large datasets, the whole process is a significant workload, and you could run it on a managed service such as Amazon SageMaker Processing, Amazon EMR or AWS Glue.
Labeling 3D Point Clouds with Amazon SageMaker Ground Truth
Let’s do a quick demo, based on this notebook. Starting from pre-processed sample frames, it streamlines the process of creating a 3D point cloud labeling job for each of the six task types (Object Detection, Object Tracking, Semantic Segmentation, and the associated adjustment task types). You can easily make yourself a private worker, and start labeling frames with the worker GUI and its labeling tools.
A picture is worth a thousand words, and a video even more! In this first video, I annotate a couple of cars using two assistive labeling features. First, I fit the box to the ground, which helps me capture object points that are close to the ground without actually capturing the ground itself. Second, I fit the box to the object, which ensures a tight fit without any blank space.

In this second video, I annotate a third car using the same technique. It’s quite harder to “see” than the previous ones, but I still manage to fit a tight box around it. Playing the next nine frames, I see that this car is actually moving. Jumping directly to the tenth frame, I adjust the bounding box to the new location of the car. Ground Truth automatically labels the eight middle frames, another assistive labeling feature called interpolation.
I’ve barely scratched the surface, and there’s plenty more to learn. Now it’s your turn!
Getting Started
You can start labeling 3D point clouds with Amazon Sagemaker Ground Truth today in the following regions:
- US East (N. Virginia), US East (Ohio), US West (Oregon),
- Canada (Central),
- Europe (Ireland), Europe (London), Europe (Frankfurt),
- Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Seoul), Asia Pacific (Sydney), Asia Pacific (Tokyo).
We’re looking forward to reading your feedback. You can send it through your usual support contacts, or in the AWS Forum for Amazon SageMaker.


